A Fujitsu jó ideje komolyan fókuszál a AI-ra, vagyis a mesterséges intelligenciára, így meglehetősen sok tapasztalatot gyűjthettek az amúgy még ma is gyerekcipőben járó irányról. Az egész alapja lényegében a deep learning, ami lehetővé teszi, hogy megfelelő adatkészlet megléte esetén a számítógép kialakíthasson olyan neuronhálókat, amelyek felhasználhatók bizonyos feladatok megvalósítására. Itt rögtön látható, hogy sok múlik az adatkészleten, ugyanis a tréning szakasz során ezek határozzák meg, hogy a neuronhálóval mire lehet menni. Hiába van tehát elméletben végtelen lehetőség ennek fejlesztésére, ha az adatkészlet nem megfelelő, akkor az eredmény csak egy nagyon szűk problémakör végrehajtására képes neuronháló lesz.
A fenti probléma az oka annak, hogy a nagyobb cégek folyamatosan gyűjtik az adatot, ez ugyanis hatalmas kincs, így biztosítható a tréning szakasz során a tesztek megfelelő mennyisége, illetve sok adat esetében aránylag nagy biztonsággal feltételezhető a kiegyensúlyozottság is. A Fujitsu azonban pusztán a tapasztalatokból is felismerhette, hogy kiegyensúlyozott és nagy adatkészletet kialakítani pokolian nehéz, így pedig hiába van meg a deep learning technológiai alapja a mesterséges intelligenciához, a tréning szakasz – pusztán az adatok miatt – sosem vagy csak elképesztően sokára adhat megfelelő eredményt.
A japán vállalat emiatt kidolgozott egy alternatív gépi tanulást, amely a wide learning nevet viseli. Ennek célja, hogy kiegyensúlyozatlan és akár kis adatkészlet mellett is belátható időn belül biztosítson egy olyan neuronhálót, amelynek a hatásfoka az adott területen elvárható minimumszint felett van.
[+]
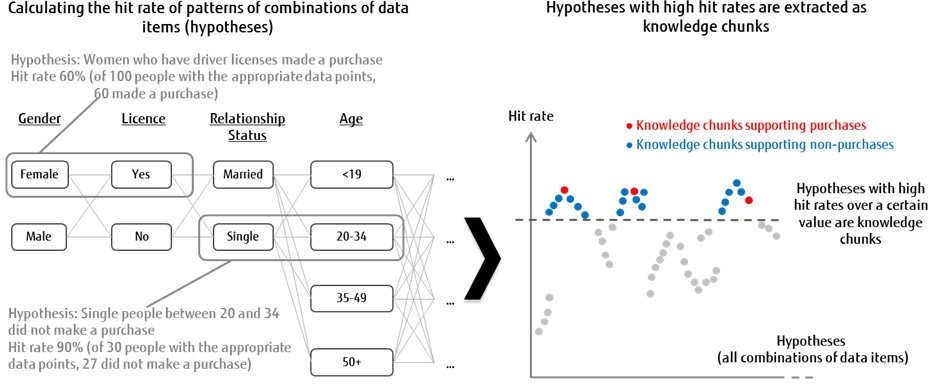
A wide learning hipotézisekként kezeli az adatelemek összes kombinációját, majd meghatározza ezek fontosságát a kijelölt kategóriában szereplő találati arány alapján. A Fujitsu példájával élve, az egyes termékek vásárlására vonatkozó tendenciák elemzésekor a wide learning kombinálja az egyes típusokat az adatelemekről, azokra kategóriákra, akik vásároltak vagy nem vásároltak. Vehetjük tehát a 20-34 év közötti, egyedülálló nőket, akiknek van járművezetői engedélyük, majd elemezhető, hogy hány találatot kaptak azok, akik ténylegesen vásároltak, amikor ezeket a kombinációs mintákat hipotézisekként alkalmaztuk. Azok a hipotézisek, amelyek találati aránya meghalad egy bizonyos szintet, fontos hipotézisnek számítanak, amit a Fujitsu tudásdaraboknak nevez. Ez azt jelenti, hogy még akkor is, ha a meglévő adatok elégtelenek, a rendszer minden olyan hipotézist kivon, ami megfontolandó, és ez hozzájárulhat a korábban nem mérlegelt magyarázatok felfedezéséhez.

[+]
A második lépésben a rendszer egy osztályzási modellt készít, amely a többszörösen kiemelt tudásdarabokon és a kijelölt kategóriákon alapul. Amennyiben itt az egyes tudásdarabokat alkotó elemek sűrűn átfednek más tudásdarabokat alkotó elemeket, akkor a rendszer csökkenti ennek mértékét, hogy befolyásolja az osztályzás modellre gyakorolt hatást. Ez teszi lehetővé a pontos osztályozást kiegyensúlyozatlan adatok esetében is.
Végeredményben a wide learning 10-20%-kal növelheti az AI pontosságát a deep learninghez képest, ha nincs megfelelő adatkészlet a tréninghez. Ez a vállalat gyakorlati mérése marketing és egészségügyi területekről.