

Az AMD visszahozta a középkategóriát
Az elmúlt években rengeteg VGA-val lepték meg a gyártók a piacot, és ezek jó része igen kellemes megoldás volt, de a vásárlók többségének valami mégis mindig hiányzott. Ha visszaemlékszünk az előző évtizedre, akkor jóval több jó vásárt lehetett kiemelni, mint az elmúlt hat évben, amiben vitathatatlanul közrejátszott, hogy a VGA-piac jelentősen szűkült, így a gyártók más területekre helyezték a fókuszt. Ennek az áldozata lett a klasszikus középkategória, vagy jobban mondva az igazi népkártyák, ami egyértelműen látszott a termékkínálaton, ugyanis megfizethető erős kártyának utoljára csak a Radeon HD 4800-as sorozaton belüli két modell számított.
Azóta sajnos mintha elvágták volna ezt az irányvonalat. Ez persze Magyarországon a forint gyengülése miatt még jobban érződött, de globális jelenségről van szó, vagyis a 200 dolláros árszintre ugyan nem érkeztek rossz VGA-k, de kiemelkedően jó befektetésnek sem számítottak.

AMD Radeon HD 4850 - az utolsó igazi népkártya
Az AMD év elején már utalt arra, hogy a Polaris család kifejezetten a középkategóriát szeretné célozni, bár akkor még túl pontos adatok nem láttak erről napvilágot, ugyanakkor az év első felében többször is elhangzott, hogy az új Radeonok a megfizethető szintre érkeznek, amiből már felmerült, hogy a piac végre újra kaphat pár olyan terméket, amelyek végre olcsón kínálnak elég sokat.
A Polaris család fejlesztésénél a legfőbb döntésnek az számított, hogy az AMD a TSMC helyett a GlobalFoundries gyártósorait használja. Utóbbi cég a megcélzott 14 nm-es LPP node-ot a Samsungtól licencelte, ami az AMD számára is kedvező, hiszen az egyes kész dizájnokat akár a dél-koreai óriáscéghez is át lehet vinni, igen csekély módosítás mellett is, ha szűkös lenne a gyártókapacitás. Ennél is lényegesebb, hogy az AMD igen speciális szerződéssel kötődik az arab tulajdonban lévő bérgyártóhoz, így amíg a TSMC-nél szinte semmi esély arra, hogy alacsony áron kapjanak wafert, addig a GlobalFoundries a legfontosabb megrendelőinek biztosít ilyen lehetőséget, persze megfelelő rendelési tétel mellett.
A wafer ára azért is fontos, mert a TSMC-nál az új generációs node-okra erős túljelentkezés van, így logikus a tajvani bérgyártó számára az árakat magasan tartani, míg a GlobalFoundries inkább az aktuális partnerek megőrzésére törekszik, miközben megpróbálnak új partnereket szerezni, vagyis számukra a legjobb fegyver a waferárak mérséklése. Ezek a szempontok játszhattak közre abban, hogy az AMD sok év után otthagyta TSMC-t, amely a GPU-kat fejlesztő cégek igényeit az elmúlt években egyre kevésbé veszi figyelembe, hiszen a rendelési tétel tekintetében alaposan elhúzott pár rendszerchipeket fejlesztő vállalat. Mindeközben a 14 nm-es LPP node a karakterisztikáját tekintve nem sokban különbözik a TSMC 16 nm-es FinFET node-jaitól, vagyis nagyjából hasonló képességekkel rendelkező lapkákat lehet rajta gyártatni.
A fenti döntéssel az AMD egyrészt esélyt kapott egy árverseny kialakítására, hiszen nem kell a TSMC már-már tényleg extrém magasságokat ostromló waferáraihoz igazodni, másrészt azonnal nagy mennyiségben tudják a lapkákat piacra küldeni, és nem kell kivárni a sorukat a tajvani bérgyártó, kisebb megrendelőket eléggé hátrányba helyező kiszolgálási modelljével. Ez a két tényező adott lehetőséget arra, hogy a VGA-piacon újra megjelenjen az igazi középkategória, amit már annyira sokan hiányoltak.
Bevetésen a negyedik generációs GCN
Az AMD az új lapkákat most nem szigetekről, hanem csillagokról nevezi el, az egyes fejlesztések között pedig számok tesznek majd különbséget. Az eligazodást ez nem könnyíti majd meg, de általában épp ez is a cél, ugyanis így pusztán a kódnév kiszivárgásából kevésbé lehet következtetni, hogy hova is érkezik az adott fejlesztés.
Az új Polaris családba két lapka jön Polaris 10 és 11 jelzéssel. Előbbi lesz a nagyobbik, egészen pontosan 5,7 milliárd tranzisztorból álló, 232 mm²-es modell, amiről jelen cikkünk is szól, így ennek az elemzésére koncentrálunk. Az új rendszer továbbra is a GCN architektúrára alapoz, de ennek már a negyedik generációs verzióját használja, amit az AMD szimplán GCN4-nek nevez.

Polaris 10 blokkdiagramm [+]
A Polaris 10-es grafikus vezérlőben 36 darab CU van, és ezek egyenként tartalmaznak egy skalár feldolgozót, illetve négy darab, egymástól teljesen független, 16 utas, azaz 512 bites, multiprecíziós SIMD motort. Egy CU-n belül 64 kB-os Local Data Share (LDS) található, melyen a négy darab, egyenként 64 kB-os regiszterterülettel rendelkező SIMD motor osztozik. Az LDS-sel az AMD – szokásához híven – túlteljesíti a DirectCompute 32 kB-os követelményét, aminek az a magyarázata, hogy az architektúrát általános számításokra tervezték, illetve a manuális interpoláció számára is szükséges némi gyorsan elérhető memóriaterület. Az AMD az LDS-t szokás szerint virtualizálja, tehát a különböző feladatok egymás adatait nem bánthatják, ezzel egyetemben a rendszer megörökölte a korábbi lapkáktól azt a tulajdonságot, amelynek hála a CU-kon belüli LDS-t a geometry shaderek adatainak mentésére is lehet használni. Az LDS mellett természetesen egy 16 kB-os adat gyorsítótár is elérhető, melyet a CU írhat és olvashat is.
A fentebb már említett skalár feldolgozó némileg különc a CU-n belül. Ez lényegében egy integer ALU, mely 4 kB-os dedikált regiszterterületet kapott. A textúrázást CU-nként egy blokk oldja meg, mely négy darab, csak szűrt mintákkal visszatérő Gather4-kompatibilis textúrázó csatornát rejt. A lapkán belül három CU egy tömbbe rendeződik, és ehhez tartozik egy 16 kB-os skalár és egy 32 kB-os utasítás gyorsítótár. Előbbit csak a skalár feldolgozó éri el, míg utóbbit a CU összes feldolgozója hasznosíthatja, de természetesen mindkét gyorsítótár írható és olvasható is.
A Polaris 10 órajelenként négy háromszöggel dolgozó setup motort használ. A négy darab tesszellátor tizenkettedik generációs megoldás, ezen belül új index gyorsítótárat kapott, míg a szintén négy darab raszter motor egyenként, órajelenként 8 képpontot dolgoz fel, vagyis összesen 32 képpontot. A memóriavezérlőhöz egy 2 MB kapacitású, írható és olvasható másodlagos gyorsítótár és 8 darab ROP-blokk kapcsolódik, ami így összesen 32 blending és 128 Z mintavételező egységet eredményez. Látható az is, hogy a blending egységek száma, illetve a raszter motorok teljesítménye szinkronban van. Némileg változott a memóriavezérlő is, amely az új lapka esetében 256 bites. Utóbbit felkészítették a magas órajelű GDDR5 memóriák fogadására.
A dupla pontossággal kapcsolatban az AMD nem volt túl bőbeszédű, de kiderítettük, hogy a hardver képes az elméleti számítási teljesítmény tizenhatod részével elvégezni a feladatokat, vagyis ebből a szempontból elég korlátozott megoldásnak számít, de a Radeonok által megcélzott piacon ez amúgy sem lényeges szempont. Sokkal érdekesebb a 16 bites lebegőpontos utasítások támogatása, amely már natívan van kezelve, ezen belül is energiát és regiszterterületet lehet spórolni a 16 bites precizitás használatával, de nem lehet megduplázni a 32 bites precizitás melletti elméleti számítási teljesítményt.

[+]
Megújult a Tonga cGPU-ban bemutatkozott Delta Color Compression technika is, amely jóval hatékonyabb lett, mivel teljes mértékben támogatja a 2:1, a 4:1 és a 8:1 arányú, veszteségmentes tömörítést, amivel jelentősen lehet csökkenteni a memóriabuszra vonatkozó terhelést. A korábbi generációs Delta Color Compression technikához képest a hatékonyság nagyjából megduplázódott.
A GCN4 nagy fejlesztése
A GCN4 az előző oldal alapján olyannak tűnik, mint a többi korábbi GCN, ez azonban csak a látszat, mivel eddig ez az iteráció számít a legnagyobb előrelépésnek a GCN-ek történelmében. A legnagyobb fejlesztés vitathatatlanul az utasítás-előbetöltés támogatása. Ez egy olyan funkció, amit a központi processzoroknál már megszokhattunk, de a grafikus vezérlőknél nem sok használt lehetett látni, így nem is került bele a rendszerekbe. A világ azonban változik, és ez magával hozza az igények módosulását is, amelyekre reagálni kell.
Ha pusztán az elméletet tekintjük, akkor utasítás-előbetöltésre egy GPU esetében nincs szükség. Hogy miért? Mert ezeket a rendszereket eleve úgy tervezik, hogy toleránsak legyenek a memóriaelérésből eredő késleltetéssel szemben, ami például a GCN architektúra SIMT modelljével is megfigyelhető. Az efféle architektúrák működésének alapja az úgynevezett wavefront, ami gyakorlatilag szálak csoportját tartalmazza, annak érdekében, hogy az egy szálhoz tartozó memóriaelérés késleltetését egy másik szál betöltése kompenzálni tudja. A logika a GCN esetében nagyon egyszerű: egy CU egy SIMD motorjára levetítve biztosan lesz elég szál, hogy elfedjék egy szál memóriaelérésből eredő késleltetését, vagyis a rendszer állandóan képes dolgozni. A megfelelő kihasználáshoz az AMD SIMD motoronként 10 wavefrontot futtat, ami a teljes CU-ra levetítve 2560 szálat garantál.
Az alábbi ábra ezt némiképp szemlélteti. Persze nem rajzoltunk be 2560 szálat és a valódi késleltetés időigényét sem ábrázoltuk, ami ezernél is több ciklus lehet, de a lényeg így is látható. A SIMD motorok a memóriaelérés miatt nem tudják folytatni a munkát az adott feladaton, így bekövetkezik az úgynevezett pipeline stall. Ilyenkor megtörténik a kérés az adatelérésre, de a következő ciklusban már átveszi a munkát a következő SIMD, majd egyszer befut az első SIMD-hez az adat és az eredeti munka folytatódik. A lényeg az, hogy a folyamatos pipeline stall ellenére is mindig van min dolgozni.
")
A pipeline stall ideálisan kezelve (a kép csak illusztráció)
A wavefront futtatása azonban nem olyan egyszerű, mint ahogyan az a fentiek alapján látszik, ugyanis a különböző shader programok eltérő regiszterterületet igényelnek, vagyis elképzelhető, hogy 10 wavefront egyszerűen nem futhat a SIMD motoron, mert nincs elég regiszter hozzá. Ilyenkor az aktív wavefrontok száma csökken. Az AMD ajánlásai szerint a GCN architektúrában 7 wavefont az a minimum mennyiség, amivel a memóriaelérés még megfelelően átlapolható.
")
A pipeline stall problémája kevés aktív wavefront, ezen belül is kevés konkurens szál mellett (a kép csak illusztráció)
A lényeg ebből már látható. Elméletben a pipeline stall nem okozhatna problémát, mert a SIMT rendszerű architektúrákba bele van tervezve maga a megoldás. A gyakorlatban azonban ez az egyszerű programokra van méretezve, ugyanakkor ma már egyre bonyolultabb shadereket írnak a fejlesztők, amelyek egyre nagyobb regiszterigénnyel rendelkeznek. Ez addig nem baj, amíg ezek a shaderek vagy inkább futószalagok a program összes futószalagjának kis részét teszik ki, de maga a trend az AMD szerint egyre inkább felerősödik, vagyis kell valami megoldás arra az esetre, amikor a hardverbe tervezett működési modell kudarcot vall. Az utasítás-előbetöltés tulajdonképpen ezért került bele a GCN4-be. Ilyen formában radikális mértékben csökken a memóriaelérés ideje, mivel az adat jó eséllyel már az igénylés pillanatában ott van a gyorsítótárakban, ahonnan jóval kevesebb idő áttölteni a regiszterekbe. Bár ettől a SIMT rendszerű architektúra alapvető működési modellje nem változik, de például a teljesítmény már nem fog összeomlani akkor, ha az adott shader regiszterigénye akkora, hogy a SIMD motoron esetleg csak egyetlen egy wavefront futhat.
")
Az utasítás-előbetöltés megoldása a kevés aktív wavefrontra, ezen belül is a kevés konkurens szálra (a kép csak illusztráció)
A megfelelő működés érdekében az AMD megnövelte a wavefrontokhoz rendelt utasításpuffert is, ami a fenti változással együtt jelentős mértékben növeli az egy szálon leadott teljesítményt. A pipeline stall mértéke a GCN4 architektúrában minden esetben jelentősen csökken. Itt tényleg nagyságrendi változásra kell gondolni, mert az utasítás-előbetöltéssel gyakorlatilag bőven 100 ciklus alá lehet vinni a memóriaelérésből eredő késleltetést. Bár magát a rendszert az AMD az új és egyre bonyolultabb shaderekhez dolgozta ki, az egész akkor is segít, ha a fejlesztők rosszul optimalizált, indokolatlanul nagy regiszterigénnyel rendelkező shadereket használnak. Ezeknél is tipikus probléma szokott lenni a pipeline stall, és ezt gondot a Polaris tulajdonképpen hardverből kezeli. Persze a rosszul optimalizált shadereket driverből is ki lehet cserélni (és az AMD, illetve az NVIDIA ezt meg is szokta tenni), vagyis ez a gond tulajdonképpen kezelhető, ugyanakkor a hardveres konstrukció így is előnyös, mivel a shaderek szoftveres úton történő cseréjére sokszor hónapokat kell várni, míg a hardveres út azonnal működik.
Az utasítás-előbetöltés a DirectX 12 és a Vulkan API mellett is lényeges előnyöket biztosít. A többszálú modellel egyszerűen annyira hatékonnyá vált a processzor oldalán történő parancsfeldolgozás, hogy bőven lehet olyan játékokat fejleszteni, amelyek tízezer rajzolási parancsnál többel dolgoznak képkockánként. Ez a DirectX 11 miatt eddig nem volt realitás, de nagyon gyorsan az lesz. A váltás miatt ugyanakkor olyan limitációk jelennek meg az aktuális hardverekben, amelyeket a DirectX 11 alatt nem lehetett kihozni. Mindmáig ugyanis nem volt fontos az a tényező, hogy az adott GPU multiprocesszorának úgymond milyen mély a futószalagozása, vagyis mennyi az az idő, ami eltelik a feladatok adatigénylése és a várt adatok beérkezése között. Az aktuális GPU-k futószalagozásának mélysége ezer és tízezer ciklus közötti.
A dolgok pikantériája itt az, hogy megfelelő programfuttatási sebességet feltételezve tízezer rajzolási parancs képkockánként már nagyjából csak 1 mikromásodpercnyi késleltetést enged meg a GPU-n belüli szálak esetében, és ha a rajzolási parancsok száma nő, akkor a bőven bele lehet csúszni a mai hardverek futószalagozási modelljének limitjeibe. Ezen a problémán is jelentősen segít az utasítás-előbetöltés, amellyel bőven 1 mikromásodperc alá vihető a futószalagidő azzal, hogy a szükséges adat igénylése az előbetöltésnek hála még a tényleges igényre vonatkozó parancs kiadása előtt megtörténik. Mindez azt jelenti, hogy a rengeteg rajzolási paranccsal dolgozó alkalmazások lényegesen jobban fognak skálázódni a Polaris családba tartozó grafikus vezérlőkön, míg a többi hardveren beleütköznek a mély futószalagozás limitjeibe.
A GCN4 furcsa fejlesztése
Az AMD egy alternatív területen is meglepően furcsa fejlesztéssel állt elő. A GCN4 másik nagy újítása ugyanis az úgynevezett primitive discard accelerator. Ez az egység a setup motor része, így minden primitív, azaz háromszög átfut rajta a primitív feldolgozás fázisában, vagyis a vertex shader lépcső után, azaz bőven a raszterizálás előtt.
Bár a grafika számításánál számos algoritmus törekszik arra, hogy a nem látható részletek még a feldolgozás előtt ki legyenek vágva, teljes megoldás erre nincs igazán, így valamennyi, alapvetően haszontalan primitív átcsusszan a szűrőn, és ezekről sajnos csak akkor derül ki, hogy nem látszanak, ha a számítások jó része már el lett végezve rajtuk. Ekkor persze ki lesznek vágva, de az erőforrások egy jelentős részét már elvitték. A jelenet komplexitásának növekedésével sajnos növekszik a végeredmény szempontjából haszontalan számítások mennyisége is, ami egyáltalán nem szerencsés a fejlesztők nézőpontjából, de ezzel a problémával együtt kellett élni.
A primitive discard accelerator célja eldönteni azt, hogy a megkapott, korábban lefuttatott kivágási rendszerek által meghagyott primitív látszik-e a végső képen vagy nem. Ezt a célhardver egy nagyon bonyolult ellenőrzési folyamattal teszteli, és sajnos az AMD nem árulta el, hogy miképp döntik el a primitívekről a vertex shader lépcső után, hogy melyek fontosak és melyek dobhatók el. A titkolózás természetesen érthető, mivel maga a problémakör régóta komoly kutatási területe a hardvergyártóknak, és gyakorlatban is működő rendszerrel eddig még senki sem állt elő.
Nyilván a primitive discard accelerator legnagyobb előnye, hogy amint megmondja egy primitívről, hogy nem fog látszani, onnantól kezdve a hardvernek nem kell törődnie tovább vele, ami lényeges előny lehet, hiszen az aktuális API-kban a vertex shader fázis után van még tesszellálás, geometry shader, raszterizálás, illetve pixel shader is, ahol komoly erőforrásokat lehet elkölteni az amúgy sem látszó elemekre.
Az AMD szerint a primitive discard accelerator változó hatékonysággal működik, mivel számít az is, hogy mennyi amúgy haszontalan primitív csusszant át a korábbi szűrőkön. Ha kevés kivágható háromszög van a jelenetben, akkor az előny százalékos léptékekben mérhető csak. Általánosan elmondható, hogy minél kisebbek a jelenetben használt háromszögek, és ezen belül is minél komplexebb a megjelenítendő jelenet, annál nagyobb előnyhöz lehet jutni a korai hardveres kivágásból.

A legnagyobb előnyt a mikropoligonokkal lehet nyerni magas MSAA mintavételezéssel. Az AMD négyszeres MSAA melletti tesszellálásnál kimérte a primitive discard accelerator által biztosított relatív gyorsulást, különböző komplexitású jelenetek mellett. Ebből az látható, hogy az új célhardver a felvázolt, elég extrémnek mondható körülmények mellett minimum kétszeres, maximum három és félszeres extra teljesítményt nyújt.
Fontos kiemelni, hogy a primitive discard accelerator sem vágja ki az összes, végső képkockán nem látható háromszöget, ugyanis a rendszer úgy van kalibrálva, hogy ha nem biztos benne, hogy az adott háromszög látszik-e vagy sem, akkor inkább átengedi. Ugyanakkor a hatékonyság így is elég nagy, és mindenképpen előrelépés ahhoz képest, mintha minden fals pozitív háromszöggel tovább kellene számolni.
A parancsmotorok és az új TrueAudio
Az általános számítások szempontjából a Polaris 10 nem tartogat sok meglepetést, a lapkán belül megmarad a négy darab ACE egység kiegészítve a két HWS (Hardware Scheduler) egységgel. Egy HWS most is két ACE egység képességeinek megfelelő tudással rendelkezik, de alapvető előnye a finomszemcsés preempció és a QoS (Quality of Service) támogatása. Előbbi felel azért, hogy a kritikus fontosságú feladatok előnyt élvezzenek, míg utóbbi a többfelhasználós környezet hatékony kezelését teszi lehetővé. A Polaris 10 extrája a változatlan compute parancsfeldolgozók mellett az ütemezés és az erőforrás-menedzsment átalakítása, amit az AMD a HWS egységekre vonatkozó mikrokód frissítésével ért el.
A változásra leginkább az új TrueAudio miatt volt szükség, ami szimplán TrueAudio Next névre hallgat, és a virtuális valósághoz készült. Ez a konstrukció alapvetően különbözik az első TrueAudio blokktól, ugyanis azzal ellentétben nem dedikált DSP, hanem egy skálázható, konkrétan a multiprocesszorokba tervezett rendszer. Ez azt jelenti, hogy a számításokat maguk a multiprocesszorok végzik, és ebben nagy szerepet játszik a korábban már taglalt utasítás-előbetöltés, ugyanis a hangok kalkulációjánál kritikus fontosságú az alacsony késleltetésű feldolgozás.
A TrueAudio Next a virtuális valóságban rendkívül fontos térhangzást biztosítja amellett, hogy képes kezelni a konvolúciós reverbeket, illetve fizikailag korrekt hangélményt tesz lehetővé. Utóbbi tekinthető újdonságnak, mivel ehhez a konstrukcióhoz sugárkövetést kell alkalmazni, amit többek között a FireRays SDK-val is meg lehet oldani.

TrueAudio Next példa [+]
Az AMD szoftverpartnere ezen a területen az Impulsonic lesz, amely cég régóta dolgozik a fizikailag korrekt hangszámításon. Ez azért fontos a vállalat számára, mert nagyon egyszerűvé teszi a TrueAudio Next támogatását virtuális valósághoz készült videojáték-motorok szempontjából, ugyanis az Impulsonic Phonon szoftvertechnológiája már integrálásra került a Unity 5-be és az Unreal Engine 4-be, valamint az Audiokinetic Wwise és a Firelight fmod middleware-ekbe. A TrueAudio Next tulajdonképpen a Phonont gyorsítja, tehát a fejlesztők számára csak ezt a szoftvertechnológiát kell engedélyezni, és a rendszer már működik is.
A TrueAudio Next a fentiek mellett skálázható is. A fejlesztők dönthetik el, hogy mennyi multiprocesszort biztosítanak a hangélmény biztosítására, amit a hardver megfelelően le is kezel. A hangszámításra dedikált multiprocesszorok egyedi ütemezéssel működnek, de elfogadnak grafikai vagy compute shadert is, tehát a programozás szempontjából különösebb megkötés nincs. Érdemes persze compute shadert írni a kedvezőbb átlapolási lehetőségek miatt.
Az eredeti TrueAudio DSP kikerül a rendszerből, ennek a helyét egy emuláció veszi át, tehát a támogatás azért megmarad. Itt szintén kritikus szerepet játszik az utasítás előbetöltés.
További adalék, hogy megújult a grafikus parancsprocesszor is, ami hatékonyabban kezeli a sok rajzolási parancs befutását. Emellett továbbra is a rendszer része maradt a két DMA motor és a 64 kB-os globális adatmegosztás, vagy más néven Global Data Share (GDS). A rendszer összességében 64 compute parancslistát kezel 1 grafikai parancslista mellett, ami egyébként lassan általánossá válik a Radeon grafikus vezérlőkben.
A virtuális valóság és a multimédia
Az AMD a LiquidVR fejlesztő- és futtatási környezetet is frissítette, amelynek egyrészt része lesz az előző oldalon taglalt TrueAudio Next rendszer, de fontos változást jelent a csökkentett minőségű leképezés is. Utóbbi az NVIDIA saját – manapság VRWorksnek nevezett – csomagjában már egy ideje benne volt Multi-Res Shading néven. Az AMD ezt Variable Rate Shadingnek nevezi, de a működési elv ettől még ugyanaz, vagyis a rendszer a sztereó 3D-s képkockának csak a középre néző szem fókuszpontjában lévő részét számolja ki teljes felbontással, míg a képkocka szélén felezett vagy negyedelt felbontással történik a számítás. Nyilván ez ront a megjelenítés minőségén, de cserébe gyorsabban lesz kész az adott sztereó 3D-s képkocka.

A Variable Rate Shading és a szemkövetés
Az AMD azonban kiegészíti egy fontos rendszerrel saját konstrukcióját, ugyanis a csökkentett minőségű leképezés egyértelmű hátránya, hogy a szem mozog a lencse előtt, vagyis nem nézi szükségszerűen a kép közepét. Ilyenkor olyan területekre is tévedhet, ahol a felbontás már nem natív, hanem csökkentett, ami nyilván minőségileg kifogásolható. Erre az esetre az AMD beépített egy szemkövető rendszert a LiquidVR-ba, amit az aktuális headsetek ugyan nem tudnak használni, de előbb-utóbb lesznek olyan konstrukciók, amelyek követni fogják a szemmozgást. Az így beérkező adatok alapján a LiquidVR a Mantle API input assembler lépcsőjében beállíthatja, hogy a kilenc nézőpontra vágott képkocka esetében a fontos, középső nézőpont mely területet fedje le, ugyanis az akkor natív felbontás mellett lesz leképezve.
További adalék, hogy a LiquidVR szoftveres kiegészítése is érkezik az év későbbi részében, ami lehetővé teszi a fejlesztők számára a DirectX 12 használatát a virtuális valósághoz tervezett játékokhoz. Mint ismeretes, ma még csak a DirectX 11-et lehet fejlesztésre használni.
Multimédiás szempontból a Polaris 10 új UVD motort kapott, amelynek a verziószáma nem derült ki, de a korábbi 6-os opcióhoz képest extra a VP9, illetve a 10 bites HEVC támogatása maximum 4K-s felbontásig 60 Hz-es frissítéssel. Javult egyébként a H.264-es formátum mellett is a dekódolás, így elérhetővé vált a 4K felbontású 120 Hz-es videók gyorsítása is.
Alaposan frissült a VCE blokk, ami szintén nem kapott verziószámot, de ettől függetlenül a H.264 mellett már képes HEVC videókat is kódolni. Az új egység teljesítménye 4K-ban 60, 1440p-ben 120, míg 1080p-ben 240 fps-re elég. Mindemellett az új VCE kétmenetes kódolást használ, ami jelentősen javít a felvett vagy streamelt videók minőségén.
A videók streamelésére, illetve ezek felvételére az AMD mostantól három szoftvert is támogat, így a Gaming Evolved applikáció mellett használható az OBS (Open Broadcaster Software), illetve a Plays.tv is.

A HDR extrája [+]
A Polaris 10 különlegessége még a HDR úgymond kvázi teljes támogatása. Utóbbit az AMD már a 300-as sorozatba tartozó Radeonokon is kezeli, mivel az oda érkező frissített lapkák a korábbi verzióknál jobb kijelzőmotort kaptak. Erről részletesebben az alábbi hírben írtunk. A Polaris termékcsalád extrája azonban a még fejlettebb kijelzőmotor, amely már a 12 bites HDR monitorokkal is megbirkózik, ráadásul a HDR tartalmakat extrém magas képfrissítési érték mellett is képes kezelni.
AVFS és WattMan
Az AMD a bérgyártó leváltásával egy járulékos előnyt is biztosított a Polaris 10-nek. A vállalat a GlobalFoundries gyártástechnológiáihoz valamivel modernebb tervezőkönyvtárakat használ, amelyeket még nem portoltak át a TSMC-hez. Utóbbi érthető, hiszen nem könnyű feladat ezeket a technológiákat a különböző bérgyártók között mozgatni, de a Polaris család esetében szerencsére erre nem is volt szükség.
A 14 nm-es LPP node használatával az AMD azokhoz a tervezőkönyvtárakhoz fért hozzá, amelyekkel az aktuális APU-kat tervezték, így be tudtak építeni olyan újdonságokat a dedikált GPU-kba, mint az AVFS (adaptive voltage and frequency scaling), aminek célja a teljesítmény-fogyasztás mutató optimalizálása. Az AMD az APU-kban használt, igen fejlett monitorozó rendszert olvasztotta bele a GPU-kba, így a Polaris 10 már nem csupán egy, hanem CU tömbönként egy, azaz összesen 12 darab hőmérsékletérzékelő szenzort használ. Ezek ráadásul nem a hagyományos DVFS (dynamic voltage and frequency scaling) konstrukcióval működnek, hanem teljesen valósidejű monitorozást biztosítanak, így a hardver az egyes helyzetekre a korábbinál sokkal hatékonyabban reagál. A lapkáról tulajdonképpen egy állandó hőtérkép készül, a rendszer ez alapján állítja be az aktuális órajelet.
Az adaptív szabályozás a dinamikusnál jóval finomabb órajelre vonatkozó paraméterezést tesz lehetővé, ráadásul a beépített szenzorok mérik a feszültséget és az áramerősséget is. A rengeteg mérés miatt a rendszer önszabályzóvá válik, vagyis nem egy előre betáplált, végletekig kitesztelt szabályrendszer szerint számolja ki, hogy az adott pillanatban milyen feszültség és órajel szükséges ahhoz, hogy stabil maradjon a működés, hanem konkrétan a GPU adott környezetben történő viselkedéséből lesz kiszámolva, hogy melyek azok a maximális teljesítményt biztosító értékek, amelyekkel a zavartalan működés biztosítható.
A kötetlenebb szabályozás következtében járulékos előny, hogy az energiamenedzsmentet nem szükséges az abszolút legrosszabb helyzetre belőni, vagyis a hardver a gyakorlatban is minden pillanatban nagyon közel tud kerülni ahhoz, amire elméletben képes. Az AVFS egyetlen hátránya az implementáció elképesztő bonyolultsága, de ez különösebb gondot nem fog jelenteni, mivel a Polaris 10 ugyan a világ legelső GPU-ja ezzel a konstrukcióval, ám az AMD szemszögéből ez már a sokadik, AVFS-t használó lapkának számít, vagyis csak arra kell figyelniük, hogy gyártópartnereik abszolút kövessék az előírásaikat. Emiatt egyébként első körben mindenki csak referenciamodellt forgalmazhatja, ami nyilván tapasztalathoz juttathatja az érintett gyártókat.
Az AVFS használata lehetőséget teremt komolyabb innovációkra is, amit az AMD ezúttal ki is használ, és lecserélik az Overdrive felületet a Radeon Software meghajtón belül. A helyére az új WattMan (Watt Manager) érkezik, amely soha nem látott paraméterezési lehetőségeket biztosít a felhasználóknak, konkrétan gyári szinten.

AMD WattMan [+]
A WattMan menün belül nem csak a maximális magórajel, hanem mind a hét aktív órajelállapot egyenként állítható, ahogy a memória-órajel egyetlen aktív állapota is, ráadásul mindegyik állapothoz beállítható a konkrét feszültségérték millivoltban. Ezek mellett konfigurálható a ventilátor fordulatszáma is, ahol beállítható, hogy a minimum mennyi legyen és milyen célfordulatot érjen el a hardver melegedésének kézben tartásakor. Ehhez kapcsolódik, hogy a szabályozást a hőmérséklethez is lehet szabni, vagyis beállítható egy abszolút maximális hőmérséklet, amit minden körülmények között tartani fog a rendszer, illetve egy célhőmérséklet, aminek tartására törekszik a VGA.
További adalék, hogy a rendszer tulajdonképpen zajszinthez is állíthatja magát, vagyis a felhasználó kiválaszt egy olyan fordulatszámot, ami számára elfogadható zajt termel, és úgy fog működni a VGA, hogy azt az értéket sose lépje át, illetve konfigurálható a TDP limit is, vagyis ha arra van igény, hogy a VGA ne fogyasszon egy bizonyos szintnél többet, akkor a WattMan gondoskodik róla, hogy ez ne történjen meg.
A fentiek kombinálásával teljesen egyedi szabálykészletek is létrehozhatók, amelyek működését a WattMan beépített profilozójával ellenőrizni is lehet. A profilozott tartományt ezután vissza lehet nézni a Radeon Software vezérlőpulton belül, és láthatóvá válik, hogy egy adott pillanatban mennyi volt a mag- és a memória-órajel, a fordulatszám, a GPU hőmérséklete, illetve valószínűsíthető kihasználtsága.
A WattMan egyébként bizonyos funkciókra levetítve visszaportolható a korábbi hardverekre is, bár arról még nincs adat, hogy az AMD ezt megteszi-e. A gond itt az, hogy egy ilyen finom beállításokat lehetővé tevő rendszer igazából csak az AVFS-sel működik hatékonyan, míg a korábbi DVFS mellett különösebb haszna nem lenne, mert a hardver képtelen annyira jó belső monitorozásra, hogy a finom beállításokat esetlegesen aktiválja.
Az AMD RX 480 8 GB
Tesztlaborunkba az AMD-től érkezett az RX 480-as videokártya, méghozzá annak a 8 GB memóriával megpakolt változata. Ez egy korai mintapéldány, doboza sem volt és körítés sem volt mellette, de a boltokban megvásárolható modell esetében természetesen ezeket nem kell nélkülöznünk. A új kártya névadása meglehetősen egyedi, az RX nem az R9-es széria római számmal jelölt utódja, és nem is a Polaris 10-et akarja ugyanilyen metódussal közölni. A rövidítés a Windowsok egyik ikonikus alakjához hasonlóan áll össze, mégpedig a Radeon eXperience szavakból. Jelentsen ez játékélményt, VR-felhasználói élményt, bármit, meg kell hagynunk, alaposan eltér az eddig alkalmazott nevezéktantól, ahol a kártyák képességei voltak fókuszban.

Az eddigi AMD referenciafelépítésekhez hasonlatos a VGA [+]
Elegáns, mattfekete műanyag burkolattal látták el az RX 480-at, ami olcsónak semmiképp sem nevezhető hatású, de nem is olyan elegáns megjelenésű, mint anno a HD 7970 referenciahűtése volt, vagy amilyenek az NVIDIA felsőkategóriás videokártyái. A burkolat nem világít sehol, feliratai csak külső fényben olvashatók. Méreteit tekintve közepes hosszúságú, két kártyahelyet foglal el, és a normál magasságon sem nyúlik túl. Megfigyelhető, hogy a PCI Express tápcsatlakozó beljebb helyezkedik el. Egyetlen, radiális kialakítású légkavarójával a meleg levegőt a gépházon kívülre fújja.

Ismét csökkent a választási lehetőségek száma a kimeneteken [+]
A kimeneti oldalon csak három DisplayPort (1.3/1.4) kimenetet találunk egyetlen HDMI 2.0b társaságában. Előbbieken biztosan működik az AMD FreeSync változtatható képfrissítési technológia, és HDR adatfolyamot is támogatnak, de az utóbbival is gond nélkül csatlakozhatunk legalább 60 Hz-es képfrissítés mellett 4K-s kijelzőre. A DVI-I kimenet az AMD kártyáiról már régebben távozott, de itt már DVI-D-t sem kapunk (HDMI-ről és DP-ról is átalakíthatjuk, ha mindenképpen ilyet használnánk). Bőségesen elegendő viszont a szellőzőnyílás, így a hűtés légárama biztosan zavartalan.

Aprócska a nyomtatott áramkör, túlnyúlik rajta a hűtés [+]
Hátulról megtekintve a DVI portot hiányolóknak azonnal feltűnhet a helye, a nyomtatott áramkört erre láthatóan felkészítették. Más komponensek üres helyét is felfedezhetjük, tehát nem lepődnénk meg, ha a későbbiekben egy ettől eltérő modellel is találkoznánk. A PCIe tápcsatlakozóból nem is készültek többel vagy nagyobbal, és a NYÁK is csak egy leheletnyivel nagyobb az R9 Nano esetében látottnál. A további terjedelemért a hűtés tehető felelőssé.

A nyomtatott áramkör és a GPU közelről [+]
A hűtés eltávolítását követően látható, hogy alaposan megpakolták a parányi PCB-t komponensekkel. 8 darab 8 gigabites memóriachipjéről hővezető szilikonbetétek segítenek elvezetni a meleget a hűtés fém keretére. A tápellátó részt a kimenetek irányában helyezték el.



Az RX 480 hűtése [+]
A leszerelt hűtő a megszokott, légcsatornás kivitelű, a mókuskerekes ventilátorral. A fémkeret nem csak merevítésre szolgál, hanem a tápellátó részleg, azaz a VRM hűtéséért is felel, a már említett memóriák hőelvezetésén túl. Burkolata hat csavarral rögzül, könnyen eltávolítható, ahogyan a GPU fő hűtőbordája sem fixen beszerelt. A moduláris tervezésből profitál a ventilátor eltávolításán mesterkedő bátor tulajdonos is, csak három csavar tartja.



A hűtés belseje [+]
Egyszerű és kisméretű alumíniumborda fogad első ránézésre, de megfordítva feltűnik a hő könnyebb és gyorsabb elosztását szolgáló vörösréz mag, mint anno az utolsó AMD Athlon XP processzorgenerációhoz csomagolt gyári hűtő. Se hőcsövet, se hőkamrát nem kapunk, de erre nincs is szükség, mert kicsi a GPU hőtermelése; a minimalista megoldás méréseink szerint így is elvégzi dolgát, azonban segít az árcédula alacsonyan tartásában. Szivacsos tömítőbetétet helyeztek el a ventilátor felőli oldalán, hogy a légáram 100%-a hasznosuljon. A hat centiméteres radiális ventilátor motorereje tetemes, 1,3 A a névleges maximális áramfelvétele, PWM szabályozásának köszönhetően azonban csak szándékosság esetén közelíti meg teljes fordulatszámát.



A tápellátás és a VRM közelebbről [+]
A nyomtatott áramkör végében, egyetlen 6 tűs PCIe tápcsatlakozón keresztül történik a GPU és a VRAM-ok áramellátása, míg a járulékos elemek az x16-os PCI Express foglalatból nyerik energiájukat. A VRM 6+1 fázisú, a tekercsek jó minőségűek, annak ellenére, hogy gyártójuk az ismeretlenség homályába vész. A terheléses tesztek alatt a VRM irányából semmilyen, napjainkban sajnálatosan gyakorta előforduló cicergést nem hallottunk!



Az alkalmazott GDDR5-ös VRAM, és a tápellátás PWM IC-je a FET-ekkel [+]
A VRM lelkét egy International Rectifier IR3567B digitális PWM vezérlő adja, ezzel már Z87-es Gigabyte alaplapokon is találkoztunk, tehát kiforrott megoldásról van szó. Ez 6+2 fázist tud maximálisan, itt a GDDR5 memóriák számára csak egyet használtak az AMD mérnökei. Az alkalmazott FET-ek a MagnaChip Semiconductor MDU1511 és MDU1514 típusjelű megoldásai. Előbbinek darabja maximálisan 100 A-es áramerősséget visel el, de az utóbbi sem panaszkodhat 66 A feletti impulzusüzemű terhelhetőségével. A tápellátás tehát elég izmosnak tűnik, hamarosan az is kiderül, hogy a tuningot hogy bírja.
A Samsung műhelyéből került ki a K4G80325FB-HC25 típusú videomemória. GDDR5 típusú, chipenként 1 GB kapacitású modellről van szó, melynek a gyári üzemfeszültsége 1,5 V, és 8000 MHz effektív órajelre hitelesítették. Ezt az AMD hajszálpontosan ki is használta, ennyin ketyeg ugyanis az RX 480 fedélzeti tára.
Tesztkonfiguráció, fogyasztás
Méréseink során törekedtünk arra, hogy a lehető legpontosabb képet kapjuk, amit olvasóink is könnyen reprodukálhatnak, így a játékok beépített benchmarkját használtuk. A tesztek egyik és legfontosabb alappillére jól bevált, X99-es tesztkonfigurációnk, mely sokaknak már bizonyára ismerős lehet. Az alaplap egy Asus X99-PRO modell, míg a processzor feladatát egy fixen 4 GHz-re tuningolt Intel Core i7-5960X tölti be, hogy minél többet ki tudjunk passzírozni a tesztelt alkalmazásból. A rendszermemória mérete továbbra is 32 GB. A HyperX Fury típusú DDR4 modulból összesen négy található az alaplapban, így azok négycsatornás üzemmódban, 2666 MHz-en hasítanak.
Az egyre csak hízó játékok okán SSD-ből már kénytelenek voltunk egy 500 GB-os modellt választani, egészen konkrétan egy Samsung 850 EVO-t, jelen tesztünkben az operációs rendszeren kívül alaposan megpakoltuk játékokkal is, amiknek a futtatása volt a feladata. Ez a hetedik alkalom, hogy a 64 bites Windows 10 Próra frissített tesztrendszerünk játéktesztek során bevetésre kerül, aminek mostanra érett be a frissítése, hiszen a DirectX 12-es mód kizárólag ezzel érhető el. A tesztrendszer további komponenseit az alábbi táblázat ismerteti.
| Videokártyák | AMD Radeon RX 480 8 GB – referencia (Radeon Software - Crimson Edition 16.6.2b) NVIDIA GeForce GTX 1080 8 GB – referencia (GeForce Game Ready Driver 368.39) NVIDIA GeForce GTX 980 Ti 6 GB – referencia (GeForce Game Ready Driver 368.39) MSi GeForce GTX 970 4 GB – Gaming (GeForce Game Ready Driver 368.39) Sapphire Radeon R9 FURY X 4 GB (Radeon Software - Crimson Edition 16.6.2b) AMD Radeon R9 290X 4096 MB - Sapphire Tri-X OC (Radeon Software - Crimson Edition 16.6.2b) AMD Radeon R9 380 4096 MB - Sapphire Nitro OC (Radeon Software - Crimson Edition 16.6.2b) |
|---|---|
| Processzor | Intel Core i7-5960X (3 GHz) – túlhajtva 4 GHz-en EIST bekapcsolva; C1E / C-state kikapcsolva; Turbo Boost kikapcsolva |
| Alaplap | ASUS X99 PRO (BIOS: 2201) – Intel X99 chipset |
| Memória |
HyperX Fury 32 GB (4 x 8 GB) DDR4-2666 (HX426C15FBK4/32) |
| Háttértár | Samsung 850 EVO 500 GB MZ-75E500 (SATA 6 Gbps) |
| Processzorhűtő | Noctua NH-D14 SE2011 |
| Tápegység | Seasonic Platinum Fanless 520 – 520 watt |
| Monitor | Acer BX320HK 4K (32") |
| Operációs rendszer | Windows 10 Pro 64 bit |

A tesztkörnyezet (a képen lévő VGA csak illusztráció) [+]
Ami a meghajtóprogramokat illeti, a Radeon kártyákat a legfrissebb, Radeon Software - Crimson Edition 16.6.2 non-WHQL béta driverrel teszteltük, az NVIDIA kártyáihoz pedig a GeForce Game Ready Driver 368.39 meghajtót telepítettük fel. A játékokat háromféle (Full HD, WQHD, 4K, azaz 1920x1080, 2560x1440, 3840x2160 képpontos) felbontásban teszteltük, a képminőséget játéktól függetlenül maximálisra állítottuk. A meghajtóprogramban mindent alapértelmezett beállításokon hagytunk, az anizotropikus szűrést, illetve az élsimítást mindig az adott játékban aktiváltuk. Korábbi szavazásunk eredménye alapján mostantól, ahol lehet, DirectX helyett a Mantle leképezőt választjuk a GCN-alapú Radeon kártyák esetében.
Játékok
- Tom Clancy's The Division (DirectX 11) – motor: Snowdrop Engine / műfaj: TPS/akció
- GTA V (DirectX 11) – motor: R.A.G.E. / műfaj: TPS/akció
- Sniper Elite 3 (DirectX 11/Mantle) – motor: Asura / műfaj: FPS/akció
- Thief (DirectX 11/Mantle) – motor: Unreal Engine 3 / műfaj: FPS/akció
- DiRT Rally (DirectX 11) – motor: EGO Engine 3.0 / műfaj: autóverseny
- Middle-earth: Shadow of Mordor (DirectX 11) – motor: LithTech Jupiter EX / műfaj: TPS
- Ashes of the Singularity (DirectX 12) – motor: Nitrous / műfaj: RTS/stratégia
- Total War: Warhammer (DirectX 12) – motor: Warscape Engine / műfaj: RTS/stratégia
- Hitman (DirectX 12) – motor: Glacier 2 / műfaj: TPS/akció
A mérésekhez használt játékok palettáját ismét megváltoztattuk kissé, és több új cím is szerepel, köztük olyan forró is, mint a Tom Clancy's The Division. Ez utóbbi csak DirectX 11-et támogat, de mostantól a VGA-tesztekből a DirectX 12-t támogató programok sem hiányoznak. Ilyen például a Hitman, a Total War: Warhammer és a legelső DX12-es cím, az Ashes of the Singularity (amelynek a napokban megjelent legfrissebb, 1.20-as verzióját használtuk).
A könnyebb és pontosabb mérés, valamint összevetés érdekében minden játéknál a beépített benchmark toolt használtuk, és az ezek által rögzített eredményeket jegyeztük fel. A grafikonokat az átlag másodpercenkénti képkockák értékei alapján rendeztük csökkenő sorrendbe, ahol a főszereplő RX 480 képességei miatt a WQHD felbontás az elsődleges szempont.
Fogyasztás
A fogyasztást konnektorba dugható, digitális VOLTCRAFT Energy Logger 4000 készülékkel vizsgáltuk. A grafikonon az egyes videokártyákkal kiegészített rendszerek fogyasztása látható alaplappal, processzorral, táppal és a többi alkatrésszel együtt, de természetesen a monitor nélkül. A méréseket a Sniper Elite 3 benchmarkja alatt végeztük, mely 2560x1440-es felbontásban került lefuttatásra. Játékkal terhelt mérés közben meglehetősen sűrűn és gyorsan ingadozik a fogyasztás, ezért ide egy olyan értéket próbáltunk regisztrálni, ami a legtöbbször villant fel az eszköz kijelzőjén, vagyis nem a csúcsértéket jegyeztük fel.
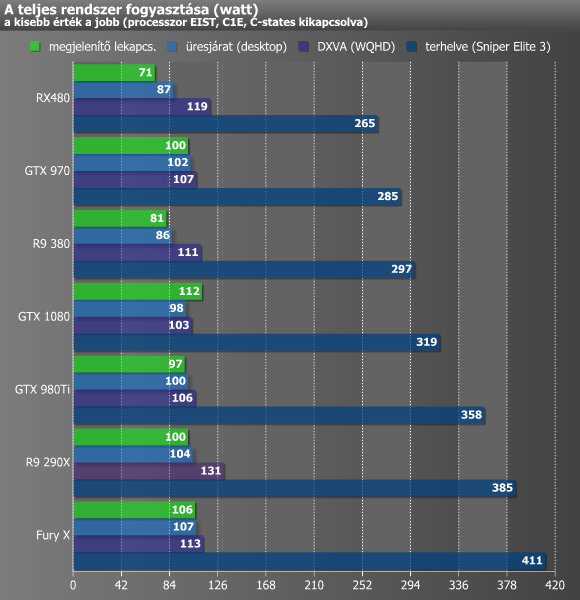
Kellemesen alacsony fogyasztási értékeket tapasztaltunk a videokártyával. Teljes terhelésen magasabb FPS-t produkált az energiahatékonyságban közismerten jeleskedő Maxwell architektúrás GTX 970-nél, alacsonyabb fogyasztás mellett. A DXVA lejátszás során csak a Radeon R9 290X-hez képest sikerült kedvezőbb értéket felmutatnia, ez remélhetőleg egy későbbi meghajtóprogrammal még javul. Az alacsony csíkszélesség viszont üresjáratban mutatta meg igazán, mit is tud: a teljes mezőnyt maga mögé utasította. Amikor megvártuk a monitor lekapcsolását is, aktiválódott a Zero Core, az RX 480 leállította a ventilátorát is, és ekkor – ettől a tuningolt géptől – még soha nem látott, alacsony fogyasztási értéket mutatott fel.
Specifikáció, hűtés
Specifikációk
Az alábbi táblázatban összefoglaltuk a Radeon RX 480 technikai paramétereit, összehasonlítva pár konkurens vagy elődmodellel.
| VGA megnevezése | Radeon RX 480 | Radeon R9 390X | Radeon R9 380X | GeForce GTX 970 |
|---|---|---|---|---|
| Kódnév | Polaris 10 | Grenada | Antigua | GM204 |
| Gyártástechnológia | 14 nm (GloFo) | 28 nm (TSMC) | ||
| Mikroarchitektúra | GCN4 | GCN2 | GCN3 | Maxwell (v2) |
| Tranzisztorok száma | 5,7 milliárd | 6,2 milliárd | 5 milliárd | 5,2 milliárd |
| GPU lapka mérete | 232 mm2 | 438 mm2 | 359 mm2 | 398 mm2 |
| GPU alap/turbó órajel | 1266 MHz | 1050 MHz | 970 MHz | 1050/1178 MHz |
| GPU/shader órajele üresjáratban | 300 MHz | 324 MHz | ||
| Shader processzorok típusa | multiprecíziós vektor | stream | ||
| Számolóegységek száma | 2304 | 2816 | 2048 | 1664 |
| Textúrázók száma | 144 textúracímző és -szűrő |
176 textúracímző és -szűrő |
128 textúracímző és -szűrő |
104 textúracímző és -szűrő |
| ROP egységek száma | 8 blokk (32) | 16 blokk (64) | 8 blokk (32) | 4 blokk (64) |
| Memória mérete | 8192 MB | 4096 MB | ||
| Memóriavezérlő | 256 bites hubvezérelt | 512 bites hubvezérelt | 256 bites hubvezérelt | 256 bites crossbar |
| Memória órajele terhelve | 2000 MHz (GDDR5) | 1500 MHz (GDDR5) | 1425 MHz (GDDR5) | 1750 MHz (GDDR5) |
| Üresjáratban | 150 MHz | 162 MHz | ||
| Max. memória-sávszélesség | 256 000 MB/s | 384 000 MB/s | 182 400 MB/s | 224 000 MB/s |
| Támogatott DirectX | 12 | |||
| Dedikált HD transzkódoló | VCE | NVENC | ||
| HD képanyagok lejátszásának hardveres támogatása | AVIVO HD (UVD) | Purevideo HD (VP4) | ||
| Hivatalos fogyasztási adat | ~150 watt | ~275 watt | ~190 watt | ~165 watt |


A Radeon RX 480-at így ismeri fel a legfrissebb GPU-Z [+]
Még a legfrissebb GPU-Z sem ismerte fel teljesen helyesen a kártya alapórajelét, de az aktuálisat hibamentesen. A tranzisztorszámot sem tudta kiolvasni, ezek a következő szoftververzióban jó eséllyel javításra kerülnek majd. Az energiagazdálkodás során a szenzorok értékeit teljesen jól mutatta, ezek voltak a valós adatok.
Hűtés
Az AMD (és az NVIDIA) referenciakártyái között idáig nem volt egy sem, amelyik üresjáratban leállítaná a ventilátorát, így ugyan csak minimális fordulaton (kb. 750 rpm-en), de üzemelt a légkavaró, miközben a grafikus mag hőfoka 35 °C körül alakult. Eközben a radiális ventilátorú AMD gyári hűtések mély, morgó hangját hallottuk duruzsolni, ami a golyós csapágyazás eredménye. Nem éles, nem magas hang, véleményünk szerint nem zavaró, nem volt hangos, csupán a jellegzetességét emeljük ki. Zárt gépházban ráadásul jóval kevésbé hallhatóan jelentkezik.

Terhelve (háromszor futtattuk a Sniper Elite 3 benchmarkját) azért felpörgött a ventilátor, és megjött a hangja is a hűtésnek. A szabályzás jellegzetessége a grafikonunkon jól kivehető, mindig emelt egy kicsit a ventilátorfordulaton a vezérlő, mert nem hagytuk a kártyát visszahűlni. Érdekes, hogy a GPU-hőmérséklet minden teszt során egy kicsit csökkent is emiatt. A 80 Celsius-fokon éppen túllőve végül nagyjából 75 °C-on állapodott meg. Mikor a terhelés megszűnt és azonnal hidegebb lett a mag, akkor sem vette vissza a fordulatszámot azonnal a tesztalany.
A terheléses mérések során a hangja nem volt zavaró hangerejű, de jól hallhatónak mondanánk, ahol a ventilátor kb. 2200 rpm-es fordulatából és a szélzajból eredő komponenseket is hallottuk. A manuálisan 100%-ra állított hűtés hangja persze borzasztóan hangos, de ezzel jó eséllyel csak azok találkoznak, akik kíváncsiságból ezt már kipróbálták, ahogy ezúttal mi is. Ekkor 5000 rpm volt nagyjából a fordulatszám.
DX11: The Division, GTA V, Sniper Elite 3



A DirectX 11 API-s címek első hullámában nincs különösebb meglepetés. Az új jövevény a Tom Clancy's The Divisionben a konkurensnek számító GeForce GTX 970 környékén teljesít, illetve közel van a Radeon R9 290X-hez. Ebből számolva közel kerülne a Radeon R9 390-hez is, de ez a VGA nem szerepel a mostani tesztben. Nagyjából hasonló a helyzet a Sniper Elite 3-ban, így a ténylegesen versenyző GeForce GTX 970, Radeon R9 290X és Radeon RX 480 majdnem azonos teljesítményt kínál.
A kakukktojás a GTA V, amiben a Radeon RX 480 az átlag teljesítményt tekintve inkább a Radeon R9 290X-hez áll közel, mintsem a GeForce GTX 970-hez, de a minimum fps-ek jobbak a többieknél, főleg magas felbontásban, illetve Full HD-ben még a GeForce GTX 970-en is túltesz. Itt mutatkozik meg először az utasítás-előbetöltés áldásos hatása, ugyanis a GTA V egy kifejezetten rosszul optimalizált port, így viszonylag sok shader túl nagy regiszterhasználattal rendelkezik, ahhoz képest, ami a realitás lenne, és ez negatív hatással van a minimum fps-re. Erre azonban a Radeon RX 480 Polaris 10 GPU-ja elég immunis, így fordulhat elő, hogy az átlag fps-hez relatíve közel van a minimum. A 4K-s értékeknél pedig a GTX 970 futott VRAM limitbe, az alkalmazott beállításokkal 4 GB feletti memóriahasználatot jelzett vissza a GTA V kezelőfelülete.
DX11: Thief, Dirt Rally, Shadow of Mordor



A fenti három játék nem tartogat sok meglepetést. A GeForce GTX 970, Radeon R9 290X és Radeon RX 480 harca kifejezetten kiegyenlített. Beállítástól függően hol az egyik, hol a másik van előrébb, de nagyon egyik VGA sem húz el. Kivételt képez ez alól a Middle-earth: Shadow of Mordor, ahol a nagy öregnek számító Radeon R9 290X egy nagyobb lélegzetvételnyi előnyt szed össze, de ez a játék a 4K-s felbontást leszámítva szinte mindegyik VGA-n játszható.
DX12: AOTS, Total War: Warhammer, Hitman
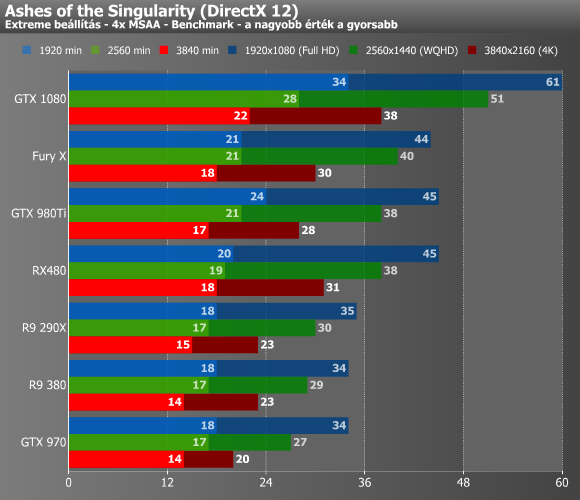


A DirectX 12-es mérések már hozzák a meglepetéseket, mivel az Ashes of the Singularity alatt az új Radeon RX 480 rendkívül erősen teljesített, még a Radeon R9 Fury X-et és a GeForce GTX 980 Ti-t is elkapta. Ez tisztán az utasítás-előbetöltés számlájára írható, ugyanis ez az egyetlen játék, ahol aktívan felkúszik a képkockánkénti rajzolási parancsok száma tízezer fölé, vagyis a többi GPU egyszerűen belefut azokba a futószalagozás mélységével kapcsolatos limitekbe, amelyeket az AMD a Polaris 10-ből kiműtött.
Ez nagyjából sejteti, hogy mennyire erős a GCN4-es alap azokban a helyzetekben, ahol az explicit API-k parancsfeldolgozásra vonatkozó hatékonyságát ki is használják a fejlesztők. A Hitman és a Total War: Warhammer esetében már inkább a saját ligájában játszik az új jövevény, de megfigyelhető, hogy a minimum fps helyenként elég erős, mondhatni relatíve közel van az átlag fps-hez, vagyis érződik az architektúrán, hogy kevésbé ütközik bele az új API-kkal felszínre bukó limitekbe a többi GPU-hoz képest.
Luxmark, CompuBench



OpenCL-es tesztjeink között a Luxmarkot már nem kell bemutatni, hiszen a LuxRenderre épülő, sugárkövetésre fejlesztett tesztprogram közkedveltnek számít, míg a CompuBench két tesztje pár fontosabb területre vonatkozóan ad némi támpontot. Ezen belül is a Bitcoin egy virtuális valuták bányászására, a T-REX pedig egy sugárkövetésre épülő applikáció, ugyanakkor a Luxmarkhoz képest az a különbség, hogy ez dinamikus jelenetet használ. A Radeon RX 480 mindegyik mérésben a Radeon R9 290X és a GeForce GTX 970 közé ékelte be magát, ami nagyjából reális lehet, de arról sajnos nincs adat, hogy az AMD a kezdeti meghajtóval mennyire optimalizált OpenCL-re.
Tuning
Már a korábbi oldalakon szó esett az AMD OverDrive-ot váltó WattMan alkalmazásról. Ezt mindenképpen ki kellett próbálnunk, mert a tuningot szerettük volna megvizsgálni, de semmilyen más alkalmazás nem ismerte még fel a címszereplőt.


Az új, WattMan nevű alkalmazást használtuk a tuningra is [+]
Meg kell mondanunk, nagyon kellemesen csalódtunk! Egyszerűen tudtuk kezelni, és természetesen amit tudtunk, maximalizáltunk. Az összes értéket manuálisan állítottuk be, de ezen a téren még érződik, hogy ez az első kiadás: például bármilyen nagy számot begépelhettünk a feszültséghez, de nem fogadta el, viszont visszaugrott az alapértékre. Rövid kísérletezéssel hamar kiderítettük, hogy 1,15 V a maximális adható feszültség a GPU-nak, és ezt alkalmaztuk is.
A VRAM-nál úgyszintén ennyit tudtunk megadni, habár ez nem közvetlen érték, hanem valamilyen offszet lehet. A ventilátor fordulatszámát 100%-ra állítottuk, aminek hatására 5200 rpm-re kapcsolt a légkavaró, így szinte majdnem felszállt tesztalanyunk. Végül a cél- és maximum hőmérsékletet fixáltuk a legmagasabb beállítható 90 °C-ra. A Power Limitet is maximalizáltuk, ez +50%-ot jelent, hogy ne (illetve minél később) avatkozzon közbe a hardveres teljesítménylimiter az ütősebb jelenetek által kikényszerített magasabb áramfelvétel során.


A tuningolt órajelek; a GPU mehetne még, a VRAM gyönyörű [+]
A tuningolási kísérleteink során a grafikus chip tekintetében 1365 MHz-ig jutottunk, ez pont 100 MHz-cel több a gyári turbó órajelnél, és 8%-os többletet eredményez, ami a fenti GPU-Z képernyőről leolvasható. A teljes terhelés mellett a 100%-os ventilátorfordulat segítségével a hőmérséklet így sem emelkedett számottevően. Az az érzésünk, hogy egy jobb hűtéssel és magasabb feszültségplafonnal biztosan több van még ebben az architektúrában.
A videomemória viszont álomszerűen viselkedett. A teljes +250 MHz-es lehetőségünket elhasználtuk a WattManon belül, és még így sem tapasztaltunk instabilitást vagy grafikai hibákat (természetesen a feszültségét itt is maximalizáltuk). Ez 12,5% emelés, és általa 9000 MHz effektív órajelen ketyegett kártyánk memóriája, majdnem elérve a GDDR5X 10 GHz-es értékét. Szerintünk ebben is van még némi tartalék.









A tuningolt videokártyával a fenti grafikonon látható teszteket futtattuk le, korrekt értékeket kapva. Sokszor a növekedés magasabb, mint ami a 8%-kal GPU frekvencia számlájára írható, itt a kitolt TDP limit miatt szerepelt jobban a videokártya.

A megnövelt GPU és VRAM órajel, valamint a feszültségemelés a Power Limit emelésével karöltve érződik az RX 480 által kért elektromosság mennyiségén is, mert így a teljes konfiguráció majdnem 100 W-tal fogyasztott többet.
Összegzés, értékelés
A mérések oldalait figyelmesen olvasók gyártói preferenciától függően most vagy nagyon örülnek, vagy kicsit kiábrándultak, az összesítésben ugyanis az RX 480 szinte pontosan az R9 290X, illetve ezáltal az R9 390 teljesítményét mutatja fel. A GTX 970-et magabiztosan utasítja hátrébb, nagyjából 8% az előnye vele szemben. Fontos adalék, hogy az összegző grafikon nem mutatja meg azt, ami a külön-külön felrajzolt játékteszteknél jól látható: a fejlett architektúra miatt kevésbé lecsökkenő értékeket, tehát a magasabb minimum fps-t, illetve a DirectX 12-es címekben is iszonyatosan erős szereplést mutatott fel az RX 480.

A fejlődést megállítani nem lehet, a DirectX 11-et használó játékok lassan, de annál biztosabban kikopnak, elavulttá válnak, helyüket pedig átveszik az explicit API-k, azok közül is kiemelten a DirectX 12. Ahogy ez a folyamat lejátszódik, úgy tolódik egyre előrébb az RX 480 az összegző grafikonon is a későbbiekben. Nem is ez a leginkább meglepő, hanem az, hogy nem sokkal maradt le a főszereplőnk a "nagyoktól", azaz a GTX 980 Ti és a Fury X mögött.

Jó pár játékban tapasztaltunk olyan fps értékeket, hogy a 2560x1440-es WQHD felbontásban magabiztosan hoz kimaxolt játékbeállítások mellett játszható sebességet. Mindamellett okosan hozzányúlva a leginkább erőforráséhes beállításokhoz, UHD (3840x2160-as) felbontásban is elérhető a folyamatos futás a játékok alatt.
A teljesítmény/fogyasztás értékekre is igaz a fenti megállapítás: minél inkább eltolódik az egyensúly a DirectX 12-es címek felé, annál feljebb fog elhelyezkedni az új Polaris 10-et használó VGA a rangsorban. A másfélszer több tranzisztort felvonultató Maxwell (GTX 980 Ti) híresen kiváló energiahatékonyságát sikerült így elérni, de az annak örökségét is magába építő Pascal (GTX 1080) egyelőre befoghatatlan. Mentségére szóljon az RX 480-nak a sokkal bonyolultabb architektúra, hiszen jól megfigyelhető, hogy a GTX 1080 kb. 25%-kal több tranzisztorral ér el 75%-kal magasabb teljesítményt. Megközelíthető ez a GTX 980 Ti felől is, amihez képest csökkent a Pascal tranzisztorszáma, de nőtt a teljesítménye.

Mindenesetre a tendencia az AMD-nél is javulni látszik, ami örvendetes. Az áramfelvétel kérdésköréhez még megjegyeznénk azt is, hogy fenti eszmefuttatásunkat kitűnően igazolja az RX 480 magas általános számítási potenciálja, ami a Luxmarkban is látható. Kevesebb tranzisztorral tört a GTX 1080 elé, ami a bonyolultabb architektúra érdeme.
Értékelés
Az eddigieket egybegyúrva számunkra kellemes meglepetéssel szolgált az AMD Radeon RX 480 8 GB-os változata. Magabiztosan utasította maga mögé legfőbb konkurensét, a GTX 970-et, mindezt 239 dolláros áron, nála kisebb áramfelvétellel és ezáltal hőtermeléssel. Amennyiben a 4K felbontás nem opció, a kisebb, 4 GB memóriát tartalmazó változat még olcsóbban, 199 dollárért nyűgözhet le minket. Az RX 480 és vele a Polaris architektúra korrekt teljesítményt kínál, a mezőnyhöz képest megfizethető áron a jelenben. Felépítésével utat mutat a jövőnek, a virtuális valóságnak és a DirectX 12-nek, mindezért ajánlott díjjal jutalmazzuk.

AMD Radeon RX 480 8 GB videokártya
Abu85, 04ahgy
Az AMD Radeon RX 480-at az AMD biztosította a teszthez.















