Az AMD sem malmozott...
Alig másfél hete mutattuk be az NVIDIA tizedik generációs grafikus processzorát, a GT200-at, az AMD részéről máris itt van a válasz, az RV770 kódnéven emlegetett GPU. A GT200 (szó szerint) nagy lett, és elméletben erős is, szóval nagy kérdés volt, most mit tesz le az asztalra a konkurens, hogyan alakulnak az erőviszonyok a gyakorlatban. Izgalmas fordulat, hogy az AMD módosította tervezési irányelveit. Az R600-zal lefektetett (de már korábban is tetten érhető) alaptézis az volt, hogy a játékok olyan irányba fejlődnek, melynél a shaderek szerepe nő meg a textúrázó egységek kárára. A már-már hitvallássá vált gondolatnak csak egy nagy hibája volt, mégpedig hogy ott volt egy ellenfél, amely nem siette el az ez irányú fejlesztéseket, és kellő piaci befolyással rendelkezett ahhoz, hogy a játékok erőforrásigénye se mozduljon el gyorsan az AMD számára kedvezőbb összeállítás felé. A mérnökök okultak a dologból, és nem csupán a shaderek számát gyarapították tovább, de ezúttal nagyobb hangsúlyt fektettek a textúrázásra és az élsimításra is.

Egy-egy szíliciumszelet RV770 és GT200-as chipekkel... [+]
Az ATI Radeon HD 4800-as sorozattal debütáló RV770 lényegében az RV670-re alapoz, de felépítése visszavezethető egészen az R600-ig, bár sok helyen módosították, finomították, sőt a memóriavezérlőt teljesen át is dolgozták. Az AMD új chiptervezési stratégiájának egyik kulcseleme, hogy előtérbe kell állítani a számítási teljesítmény/fogyasztás, illetve a számítási teljesítmény/ár arányt. Ez az igény legkorábban a központi processzorok tervezésénél merült fel, ám más szegmensekben is egyre nagyobb jelentőséget kap, gondoljunk csak a néhány hónapja megjelent platform alapjául szolgáló AMD 780G chipsetre.
Ezzel párhuzamosan fordítottak a GPU-k bevezetésének menetrendjén is, aminek kommunikálása újabb pengeváltásra adott okok az AMD és az NVIDIA között. Az előbbi ugyanis kifejezetten a tágan értelmezett középkategória számára fejlesztette új GPU-ját, azt vallva, hogy elsőként a legnagyobb piaci szegmensben kell hozzáférhetővé tenni az új technológiákat, majd fölfelé és lefelé történő skálázással következhet a csúcskategóriába, illetve a belépőszintre szánt videokártyák elkészítése. Az NVIDIA ezzel szemben még a hagyományos receptet követi, a GT200-zal a felső szinten vetné meg a lábát, aztán ha már beáll a gyártás, jöhetnek a teljesítményben és persze méretben is kisebb GPU-k. Az AMD az ellenfél megoldására utalva azt hangoztatja, hogy a nagyméretű „megachipek” kora lejárt, az NVIDIA pedig igyekszik azt a látszatot kelteni, hogy a vetélytárs azért a középszegmensre koncentrál, mert erre futja erőforrásaiból. Természetesen az AMD sem akar kivonulni a relatíve csekély forgalmat generáló, de komoly presztízst jelentő csúcskategória piacáról, csak éppen másképp képzeli el a megvalósítást. Nem véletlen, hogy annyira tolja a CrossFire(X) szekerét, a cégnél nagyon hisznek a multi-GPU-s megoldásokban. Mi következik mindebből? Az, hogy az AMD nem nagyméretű chipek köré építené legerősebb videokártyáit, hanem inkább két kisebb GPU-t helyezne egy nyomtatott áramköri lapra, vagy azt tanácsolja a fejleszteni kívánóknak, hogy második, harmadik vagy akár negyedik videokártya üzembe állításával fokozzák a teljesítményt. Mindehhez elegendő egy megfizethető, viszonylag egyszerűen megtervezhető és legyártható chip is, amivel több legyet üthetnek egy csapásra. Egyrészt kezükben lesz egy könnyen eladható, „best buy” videokártya, másrészt a CrossFire révén két effajta chip összekötésével szinte azonnal kiadhatnak egy csúcskategóriás terméket is (azaz mindjárt két árkategóriát fedhetnek le egy GPU segítségével). És még nem szóltunk a kisebb gyártási költségekről, az alacsonyabb selejtarányról, a kisebb fogyasztásról...
Most pedig lássuk címszavakban, hogy mit várhatunk az új architektúrától:
- tervezési hatékonyság (magméret optimalizálása, teljesítmény/ár és teljesítmény/fogyasztás arány javítása)
- 800 darab stream processzor
- optimalizált textúrázók
- új textúracache felépítés
- új memóriavezérlő
- optimalizált ROP-ok
- továbbfejlesztett geometriai shader és a tesszellációs teljesítmény

Az RV770 felépítése [+]
A tervezés hatékonyságának tekintetében az AMD a jelek szerint tényleg nagyot alkotott, ugyanis a tranzisztorszám és a magméret csak 40%-kal nőtt, miközben a teljesítményt befolyásoló részegységek száma 2–2,5-szerese az RV670-ben találhatónak. Hogy ezt miként érték el, arra csak következtetni tudunk, ennél fontosabb, hogy ez a gyakorlatban mekkora valós sebességnövekedést eredményez. Még egy érdekesség: a gyártó szerint az egy négyzetmilliméterre vetített teljesítmény 70 százalékkal több, mint az előző generációnál.
A mérnökök úgy gondolták, hogy nincs okuk hozzányúlni az ALU:TEX arányhoz, azaz a számolók és textúrázók egymáshoz viszonyított számát nem változtatták meg (bár itt van egy kis csavar). Ez persze egyáltalán nem jelenti azt, hogy nem történt változás, hiszen csak az arány nem változott, a stream processzorok száma 320-ról 800-ra nőtt (10 darab 80-as SIMD tömb), ezzel arányban a textúrázóké pedig 16-ról 40-re (a címzők és szűrők egyaránt). Nehéz lenne megmondani, hogy a textúrázók számát az NVIDIA által „támogatott” játékok hatására növelték-e meg, vagy az AMD egyébként is ezt tervezte. Mindenesetre akármennyire is feleslegesnek tűnik ez 2008-ban, nem rossz az ötlet, mert ezen a területen a Radeonok hátrányban voltak a GeForce-okhoz képest. Nem mellékes, hogy a számolók esetében is rájuk fért a gyorsulás. Az RV670-ben található 320 stream processzor számszerűleg jóval több, mint a leggyorsabb GeForce-okban található 128 számoló, de figyelembe kell venni, hogy a GeForce-ok shader órajele közel kétszerese a GPU alapórajelének. Másrészt, mint tudjuk, a Radeonok esetében 5 utas szuperskalár shader processzorokból épülnek fel a SIMD tömbök, négy skalár és egy komplex végrehajtót találunk bennük, melyek csak akkor működnek optimális kihasználtsággal, ha az egyes végrehajtandó utasítások között nincs függőség. A 10 darab 80 stream processzoros tömbhöz egyenként 16 kB lokális gyorsítótár tartozik, a többi SIMD tömbbel pedig egy globális gyorsítótáron keresztül kommunikálnak, melynek mérete szintén 16 kB. Az 5 utas shaderprocesszorokkal kapcsolatban a dokumentumok kitérnek arra is, hogy az egész számokon végzett biteltolást 12,5-szer gyorsabban hajtják végre, mint elődeik.

Textúrázók [+]
A textúrázók esetében az első lényegi újítást már említettük, az RV770-ben immár 40 textúrázó, pontosabban 10 textúrázóblokk található (ugyanis ezek egy-egy SIMD tömbhöz kapcsolódnak, márpedig ezekből négy helyett immár tíz van). De ez csak a szűrők esetében jelent két és félszeres szorzót, ugyanis címzőkből az RV670-ben 32 darab található (még ez is 25%-os többlet). Talán még ennél is fontosabb változás, hogy megújult a cache-hierarchia: az L1 textúracache nem közvetlenül kapcsolódik a textúrázókhoz, hanem egy adatlekérdező buszon (Data Request Bus) keresztül, ráadásul nem egy közös L1 textúra-gyorstárat találunk a chipben, hanem – ha írásról (store) van szó, akkor – minden egyes SIMD tömbhöz kapcsolódik külön-külön egy. Valószínűsíthető, hogy olvasásnál a SIMD tömbök a Data Request Buson keresztül használhatják egymás adatait is. Az L2 cache elérhetősége is megváltozott, ugyanis ez nem közvetlenül az elsőszintű gyorstárakhoz kapcsolódik, hanem furcsa mód az egyes memóriacsatornákhoz, de erről még később szólunk.
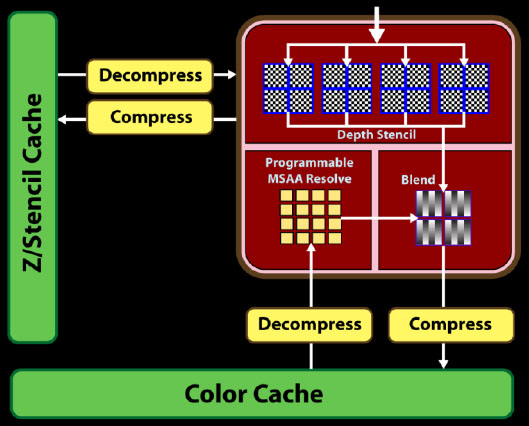
ROP egységek [+]
A ROP-ok fejlesztésével az AMD az élsimítás teljesítményén kíván javítani. A ROP blokkok száma maradt négy, de a depth/stencil írás/olvasás kétszer gyorsabb lett elődjénél, tehát 64 pixel/órajelre képes.
A leírás említést tesz még a geometriai shader feldolgozási sebességének gyorsulásáról, amit többek között úgy értek el, hogy a chip több geometriai shader által generált adatot képes egyidejűleg kezelni és tárolni (több a gyorsítótár), illetve négyszeresére nőtt a kezelt GS-szálak száma is. A tesszelációt is továbbfejlesztették, mely alkalmazható replikáció (instancing) esetén is, és támogatja a DirectX 10.1-et.
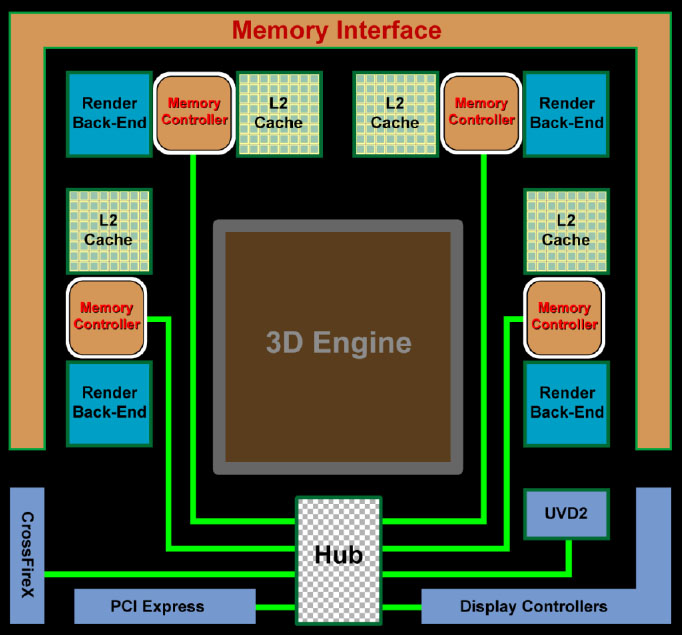
Hub-központosított felépítés [+]
Az RV770 eddig ismertetett újításai nem voltak különösebben meglepőek, de az, hogy hozzányúltak a ring-bus memóriavezérlőhöz, váratlanul ért minket. Bármennyire is meglepő, az AMD eldobta a ring-bus memóriavezérlőt, és helyette kifejlesztett egy hub által összekötött megosztott memóriavezérlőt. Nem teljesen egyértelmű, hogy a hubra pontosan milyen memóriavezérlő csatlakozik: egyetlen négyirányú vagy pedig négy különálló. Ami biztos, hogy a négy végponthoz az elsődleges sávszélességfaló komponensek kapcsolódnak, úgy mint az L2 gyorstár és a ROP egységek. Minden más, a parancsfeldolgozó, a számolók és a textúrázók is csak a hubon keresztül érik el a memóriát. A videolejátszást gyorsító rész (Avivo HD, UVD2), a PCI Express és a CrossFire vezérlő, illetve a megjelenítésvezérlő is csak a hubot látja. Az AMD szerint ez a memóriafelosztásos módszer csökkenti a késleltetést és a fogyasztást is. Az új memóriavezérlő immár támogatja a GDDR5 szabványt, melynek elsődleges szerepe a sávszélesség növelése. Az új chipek lábanként 3,2–3,7 Gbps tempójú adatátvitelt tesznek lehetővé, vagyis chipenként 12,8–28 GB/s sávszélesség érhető el. Mindez nem csupán a teljesítmény fokozását szolgálja, hanem inkább a teljesítmény és a költségek közötti egészséges kompromisszum megteremtését. Ha ugyanis ugyanakkora sávszélesség kevesebb chippel is elérhető, akkor csökken a nyomtatott áramkör mérete, bonyolultsága és persze költsége, és nem mellékesen a fogyasztási keretet sem terhelik plusz memórialapkák. A GDDR5 a megbízhatóságot növelő, az átlagos felhasználó számára rejtve maradó funkciókat is kapott; minden tranzakció hibaellenőrzéssel párosul, és ha a vezérlő azt érzékeli, hogy a hibaarány elér egy küszöböt, akkor újra megtörténik a GPU és a RAM szinkronizációja.
Az NVIDIA-hoz hasonlóan az AMD is igyekszik hangsúlyozni, hogy az új chip már nem csak egy szimpla grafikus gyorsító, hanem ha GPGPU feladatokról, azaz általános jellegű számolnivalóról esik szó, akkor is egy komplett erőmű. Az RV770 órajeltől függően 1 teraFLOPs-os teljesítményével felülmúlja még az NVIDIA GT200-as chipet is, ráadásul számos optimalizációt is elvégeztek rajta (melyekről már szó esett: nagyobb gyorsítótárak, gyorsabb egészműveletek, gyorsabb memóriaműveletek), melyekkel az előző generációhoz képest is számottevően gyorsulnak a kalkulációk. (Az 1 teraFLOPs persze egyszeres pontosságú számításokra értendő, kétszeres pontosságnál 240 gigaFLOPs az idevágó érték.) A játékokra visszatérve: a nagy számítási kapacitást a jövőben nem csak a grafikánál használhatják ki, az AMD szerint a CPU erőforrásait jelentős mértékben lefoglaló mesterséges intelligencia is – részben – a GPU-ra költözhet, így nemcsak növelhető a gép által generált karakterek száma, hanem viselkedésüket sem kell előre kitalált minták permutációjával előállítani, helyette megnőhet a valós idejű döntések szerepe. A másik növekvő jelentőségű terület a fizikai modellezés. Az Ageia felvásárlásával az NVIDIA a PhysX API mellett tette le a voksát, az AMD viszont a szélesebb körben használt Havoktól licenceli az ehhez szükséges technológiát. A helyzet akkor válhat még érdekesebbé, ha majd az Intel is beszáll a videokártyák piacára, hiszen a Havok tulajdonosaként nem kétséges, melyik fizikai API-t fogja támogatni.
Az NVIDIA továbbra sem támogatja a DirectX 10.1-es változatát, mondván a 10.0-hoz képest olyan elhanyagolható a kiterjesztés, hogy felesleges vele foglalkozni. A kérdésben valószínűleg sosem fogunk teljesen tisztán látni, az AMD szerint azonban nem pusztán az szól a 10.1 mellett, hogy bizonyos esetekben állítólag 10–20 százalékos gyorsulás érhető el vele. Legalább ilyen fontos érvnek tartják, hogy vannak olyan összetett effektusok, amelyek sokkal könnyebben leprogramozhatók a kiterjesztésnek köszönhetően, vagyis munkát és időt takarítanak meg a fejlesztőknek. Hogy pontosan mi van a háttérben, nem tudjuk, de Malagában azt hallottuk, hogy a közeljövőben az eddigi tartózkodás ellenére mégiscsak gyarapodni fog a DirectX 10.1-kompatibilis címek száma. Itt említjük meg, hogy a SEGA is készül valamivel, amiről egyelőre nem árultak el semmi érdemit, de láthatóan nagy várakozásokat fűznek új játékukhoz.
Az RV770 funkciólista részét képezi az Avivo HD kiterjesztése is, amely az UVD2, azaz Unified Video Decoder 2 nevet viseli. Ez lényegében az AMD-nek az NVIDIA G92 és G94 chipjeiben megjelent funkciókra adott válasza, illetve annál még egy kicsit több is. Részét képezi a már ismerős Dual Stream Playback (NVIDIA-nál Dual Stream Decode Acceleration) technológia, amely lehetőséget ad két HD videó szimultán lejátszására, kép a képben módon. Fejlődött a videók dinamikus kontrasztjának beállítása is, továbbá színek, tónusok valós időben feljavított megjelenítése. Újdonság a DVD-ből Full HD (vagy ahhoz közeli PC-monitoros) felbontásra skálázás (például 720x576-ról 1920x1200-ra), amit az UVD2 a különböző videolejátszó szoftvereknél elvileg szebben jelenít meg. Bizonyára egyre többen örülnek majd az RV770-re épülő videokártyák esetében az új, 7.1 surround hangzást is átvivő HDMI csatlakozónak (192 kHz, 24 bit, AC3/DTS/Dolby True HD/DTS HD).
Eddig csak a teljesítménnyel kapcsolatos változtatásokról esett szó, ugyanakkor nem mehetünk el szó nélkül az RV770 energiagazdálkodási sémái mellett sem. Az NVIDIA a GT200-ban bemutatta az órajelkapuzást, amit a GPU-k esetében már nagyon régóta hiányoltunk. Az AMD is megvalósított valami ehhez hasonlót, vagyis mód van a chip egyes egységeinek energiatakarékos üzemmódba kapcsolására. Az RV770-ben található egy mikrokontroller, mely a GPU egyes részeit, illetve a PCI Express buszt figyeli, és ha lehetősége van rá, akkor órajelet csökkent a GPU és a memória esetében is, illetve mindezek alapján a ventilátort is szabályozza.
ATI Radeon HD 4850
A gyártó egyelőre csak egy új videokártya értékesítését kezdte meg, ez a Radeon HD 4850 (a HD 4870 kicsit később jön). A cég a HD 3800-asoknál egy újfajta modellszámozási sémát vezettet be, emiatt eltűnt a Pro és XT utótag, ellenben a Radeon HD elnevezés utáni, négy számjegyű kód utal az adott VGA sebességére. Az első számjegy a generációt jelképezi a PCI Express időszámítás szerint, a második a termékcsaládot határozza meg, az utolsó kettő pedig az ezen belüli relatív teljesítményviszonyokat hivatott tükrözni. Ebből következik, hogy a HD 4850 felfogható a régi rendszer szerinti 4800 Próként.

Radeon HD 4850 [+]
A két Radeon ezúttal is lényegében ugyanarra a felépítésre alapoz, de az órajelek, a hűtés és a felhasznált memóriachipek generációjukban eltérnek majd egymástól. A Radeon HD 4850 külsőre sokaknak igen ismerősnek tűnhet, ugyanis szinte teljes mértékben megegyezik a Radeon HD 3850-nel. A GPU 625 MHz-en, a memória pedig 1 GHz-en üzemel, a HD 4870 majd 750/1800 MHz-es órajelekkel kerül forgalomba.



![]()
Radeon HD 4850 [+]
A videokártyán található hűtés majdnem megegyezik a HD 3850-en is látott egyszlotos megoldással. Ez egy egyszerűbb, a GPU-t és a memóriákat együttesen beborító réz hűtőborda, ventilátora 2D-ben és 3D-ben egyaránt lassú és hangtalan, ami jól hangzik, de nem kellett még játszanunk sem ahhoz, hogy az egész videokártya felforrósodjon, még hozzáérni is alig lehet, ami a komponensek számára nem éppen ideális állapot. Az előző generációhoz képest viszont több lapátból áll a ventilátor, és a hűtőbordában található lamellák is sugárszerűen helyezkednek el, ami egyben azt is jelenti, hogy több levegő tud rajtuk átáramlani. Maga a NYÁK nagyon hasonlít a HD 3800-asokéhoz, néhány alkatrész odébb került, több lett a kondenzátor, de a legszembetűnőbb, hogy az összes memóriachip derékszögben helyezkedik el a GPU körül. A HD 4850 is CrossFireX-kompatibilis, tehát két CrossFire-csatlakozót találunk rajta. A videokártya szokás szerint két DVI-I és egy tévékimenettel rendelkezik, adnak hozzá HDMI adaptert is.


RV770-es GPU és a HD 4850-en található memória [+]
Az RV770-es chip alapterülete 260 mm², ez 40%-kal nagyobb, mint az RV670. Az igaz, hogy több tranzisztor jobban melegszik, de legalább nagyobb felületen oszlik el a hő (ha már pozitívumokat keresünk). A chip felirataiból nem tudunk meg túl sokat, érdekességként érdemes megemlíteni, hogy ez a lapka 2008 huszadik hetében készült, tehát valamikor május közepén, mondhatni még friss és ropogós. A GDDR5-ös chipek egyelőre nem túl gyakoriak (bár már a Samsung, a Hynix és a Qimonda is megkezdte a tömegtermelést), a HD 4850-en is csak szimpla GDDR3-as lapkákat találunk HYB18H512321BF-10 felirattal, ami 1 ns-os késleltetésre utal, ez éppen elegendő az 1000 MHz-es alapórajelhez.
Szimplán GeForce GTX

Built by NVIDIA GeForce GTX 260 [+]
Az NVIDIA újonnan bejelentett grafikus chipjével részletesen foglalkoztunk előző cikkünkben, most lássuk, hogy milyen köréje épülő videokártyákat találunk a boltok polcain. A GT200 egy nagyméretű chip, és ugyanez elmondható a köréje épülő GeForce GTX 280-ról és 260-ról is. A GTX 280, a csúcsok csúcsa, egy teljes értékű GT200-as lapkára épül 240 stream processzorral, 80 textúrázóval, 512 bites memóriavezérlővel és 1024 MB memóriával. A GTX 260-ra azok a GT200-as chipek kerülnek, melyek nem sikerültek tökéletesre a gyártás folyamán, de még van 192 darab ép stream processzoruk (8 TPC), 64 textúrázójuk, 7 ROP blokkjuk és ebből következően 7 memóriacsatornájuk (448 bites memóriavezérlő). A GTX 260-ra „csak” 896 MB memória kerül. A GeForce GTX 280 és a 260 külsőre szinte teljesen megegyezik egymással, csak egy kis különbséget lehet közöttük felfedezni: a 280-ason 8+6 tűs tápcsatlakozókat találunk, míg a 260-on két hattűsön keresztül kell tápot adni a VGA-nak.





GeForce GTX 280/260 [+]
A videokártyá(ko)n látható hűtés a 9800 GTX-en és a 9800 GX2-n megismert konstrukciók keveréke. A kártya szemből nagyjából úgy néz ki, mint a 9800 GTX, a kétszlotos csatlakozópanel egyik oldalán szellőzőnyílásokat látunk, innen indul el a nagy „motorháztető”, ami alatt a hűtőbordát találjuk, majd még beljebb haladva megpillanthatjuk a gyárilag 40%-os sebességen, csendben pörgő ventilátort. Ugyanakkor a túloldal már nem csupasz (mint a 9800 GTX), hanem ugyanúgy, mint a 9800 GX2-n, egy bordás burkot hordoz. A hűtőrendszert szétszedve látható is, hogy miért: a NYÁK mindkét oldalán vannak memóriachipek, amiket hűteni kell. A nyomtatott áramkör leginkább a G80-ra épülő GeForce 8800 GTX/Ultráéhoz hasonlít, de ez csak nagy vonalakban igaz, és leginkább amiatt, mert az óriási GPU látványa arra emlékeztet minket. A videokártya áramellátós része teljesen máshogy épül fel és a GTX 280/260-on oldalanként csak 8 memóriachipet találunk (a 8800 GTX/Ultrán 12 volt, de csak az egyik oldalon). Két-két chip alkotja a nyolccsatornás (crossbar) vezérlő egy-egy 64 bites ágát, így jön össze az 512 bites memóriavezérlő (8 x 32 bit). Ugyanakkor megmaradt a 3 utas SLI támogatásához szükséges SLI-csatlakozópár, és újra előkerült a RAMDAC-okat rejtő chip is, melyet a GPU-n kívül helyeztek el, valószínűleg annak már enélkül is óriási mérete miatt. A GT200-alapú videokártyákon két DVI csatlakozót és egy tévékimenetet találunk, furcsa, hogy a HDMI lemaradt (bár több gyártó pótolja ezt a hiányt).


A GPU és mellette az RV770-hez viszonyított mérete [+]
A GTX-ek alapjául szolgáló GT200-as lapka alapterülete több mint kétszerese a most megjelent RV770-ének. Ez persze áldozatokkal jár, gondoljunk csak a fajlagos gyártási költségekre, ami a chip méretének növekedésével egy bizonyos ponton túl exponenciálisan növekszik, hiszen minél nagyobb chipet kell legyártani, annál kevesebb fér egy szilíciumostyára, illetve annál nagyobb az esélye a meghibásodásra. Kétségtelen, hogy az NVIDIA a GTX-eket a csúcskategóriába szánja, lényegében úgy képzeli el ezt az egészet, hogy versenytársak nélkül bármilyen árat szabhat termékeinek, de ezzel csak részben lehet megmagyarázni egy ekkora chipet. Az már most biztosra vehető, hogy ezeket a videokártyákat nem fogják 50 000 forintért eladni, sokkal hamarabb ki fogják vonni a forgalomból, mint hogy erre az árszintre süllyednének.


A GTX 260 és 280 memóriái [+]
A két GTX nemcsak az aktív részegységek számában, de órajeleiben is eltér egymástól. A GTX 280 GPU-ja 602, stream processzorai 1296, memóriája pedig 1107 MHz-en ketyeg, ezek az órajelek karcsúnak tűnnek a G92-alapú GeForce-okéhoz képest, de minél nagyobb egy chip, annál nehezebb azt magas órajelen járatni, fejlettebb órajel-disztribúcióra van szükség. A GTX 260 még ennél is alacsonyabb, 576/1242/999 MHz-es órajelekkel rendelkezik. Mindkét típuson Hynix gyártmányú, H5RS5223CFR jelölésű GDDR3-as memóriák vannak, a GTX280-on található maximum 1200, a GTX 260-on található pedig 1000 MHz-et bír el a gyártó adatai szerint.

Méretek [+]
Hosszra az új GTX megegyezik a 9800 GTX-szel és a Radeon HD 3870 X2-vel, tehát nem kell miatta új házat venni (feltételezve, hogy már előtte is valamelyik csúcskategóriás VGA-t birtokló felhasználóról van szó).






{kind=link}
{kind=link}
{kind=link}
{kind=link}