
Zen harmadszor
Három és fél éve annak, hogy az AMD bemutatta az első generációs Zen magot, amely sokat javított a cég akkori pozícióján, de az igazi sikerek az előző év nyarán, a Zen 2-vel kezdtek érkezni. Október elején azonban a cég már a Zen 3-mat leplezte le, vagyis kifejezetten őrült fejlesztési tempóra kapcsoltak, köszönhetően az előző generációban behozott chipletfelépítésnek.
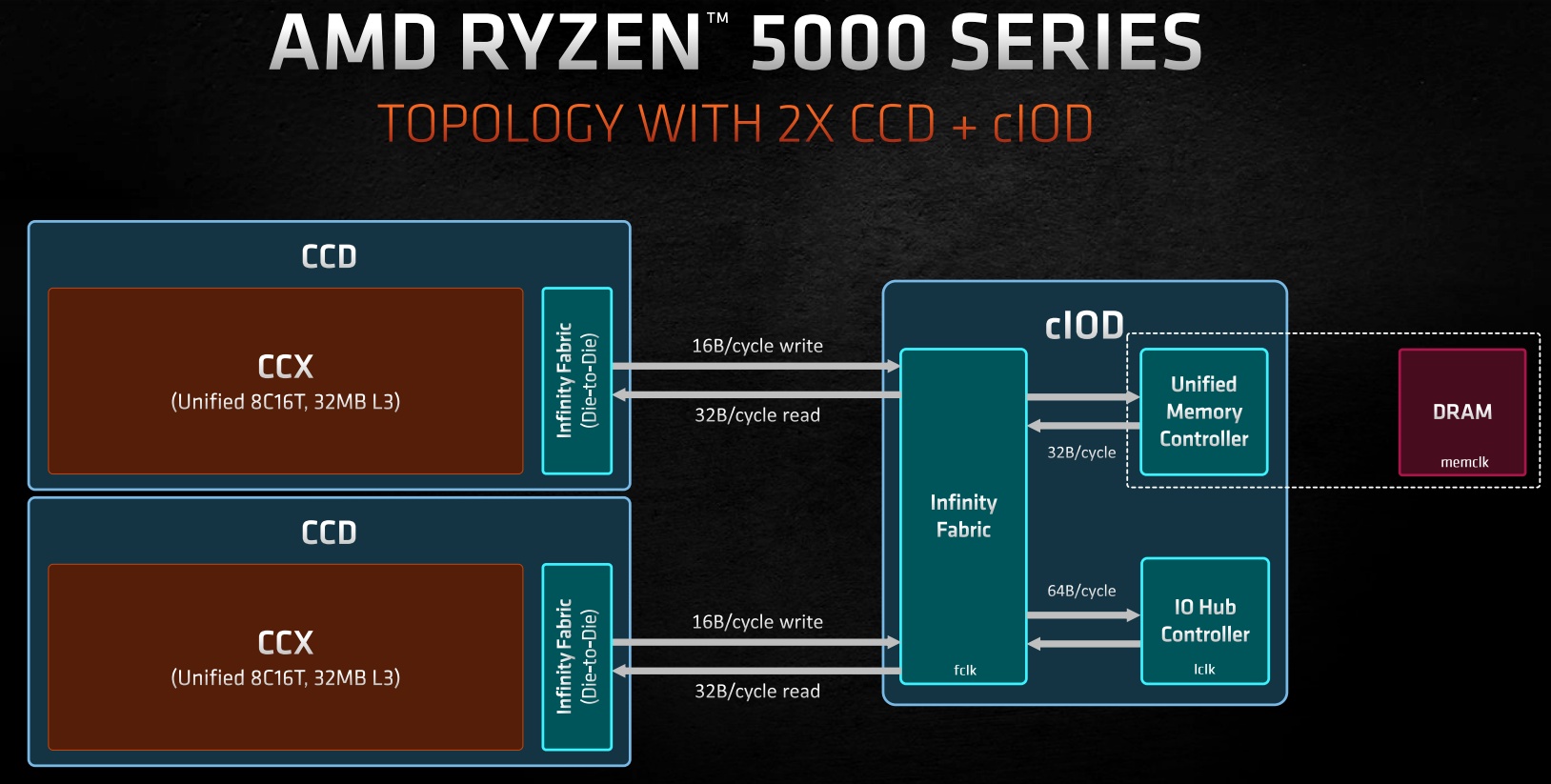
Az AMD a Ryzen 3000-es CPU-kkal két részre bontotta a tervezést, így a tokozásra egy IO lapka (cIOD) mellé került egy vagy két CPU chiplet (CCD). Az IO lapka fontos elem, de nem kell belőle minden generációban újat tervezni, és ezzel a lehetőséggel a vállalat a nemrég leleplezett Ryzen 5000-es CPU-knál él is, vagyis az új, Vermeer kódnevű fejlesztés csak a CPU chiplet tekintetében frissít. Ilyen formában marad a Socket AM4-es tokozás, ami továbbra is 1331 tűvel kapcsolódik az 500-as sorozatú alaplapokhoz. Később a 400-as vezérlőhidakhoz is megérkezik az opcionális támogatás, de ezek alkalmazása az alaplapgyártókon is múlik.
A fejlesztés tehát teljes egészében a CPU chiplet körül forgott, de ezen belül van rendesen újdonság, ugyanis nemcsak a magok, hanem a strukturális felépítés is módosult. Maga az új CCD egyébként továbbra is a TSMC 7 nm-es eljárásán készül, de már 80,7 mm² a kiterjedése és 4,15 milliárd tranzisztorból épül fel.

 [+]
[+]
Ahogy fentebb említettük, egy tokozáson belül egy vagy két CPU chiplet lehet, ezek pedig Infinity Fabric linken keresztül kapcsolódnak az I/O lapkához. Írás során 16, olvasásánál pedig 32 bájt adat mozgatása lehetséges CCD-nként.

[+]
Az igazán mély változások inkább a CCD-n belül találhatók, ez ugyanis a korábbi kettő helyett már csak egy CCX-et, azaz Core Complexet tartalmaz. Ilyen formában a CCD maga a CCX, amiben nyolc darab Zen 3 mag található, és ezekhez 32 MB megosztott, 16 utas L3 gyorsítótár kapcsolódhat a ciklusonként 32 bájtot továbbító buszon keresztül. Ez ráadásul úgynevezett victim cache, vagyis ha a magonkénti 512 kB-os, nyolcutas L2 gyorsítótár megtelik, akkor kerülnek az L3 gyorsítótárba az adatok. Továbbra is megmarad a rendszernek az a tulajdonsága, hogy az L3 gyorsítótár elérésének késleltetése nem csak az adott maghoz tartozó szeletre levetítve alacsony, hanem konkrétan az egész CCX-en belül az, és mivel már négy helyett nyolc mag osztozik rajta, ez hatalmas előnyt jelent a gyakorlati működés során.

[+]
A chipletek összeköttetésével kapcsolatban megjegyzendő, hogy változik az Infinity Fabric órajele. Bár a memóriavezérlő nem módosult, elvégre nem készült új IO lapka, viszont az optimális effektív memória-órajel 4 GHz-re nőtt, vagyis a memória ezen a frekvencián van szinkronban az Infinity Fabric sebességével, így ez adja a legjobb késleltetési értékeket – alatta és fölötte ezek romlani fognak.
A Zen 3 mélylélektana
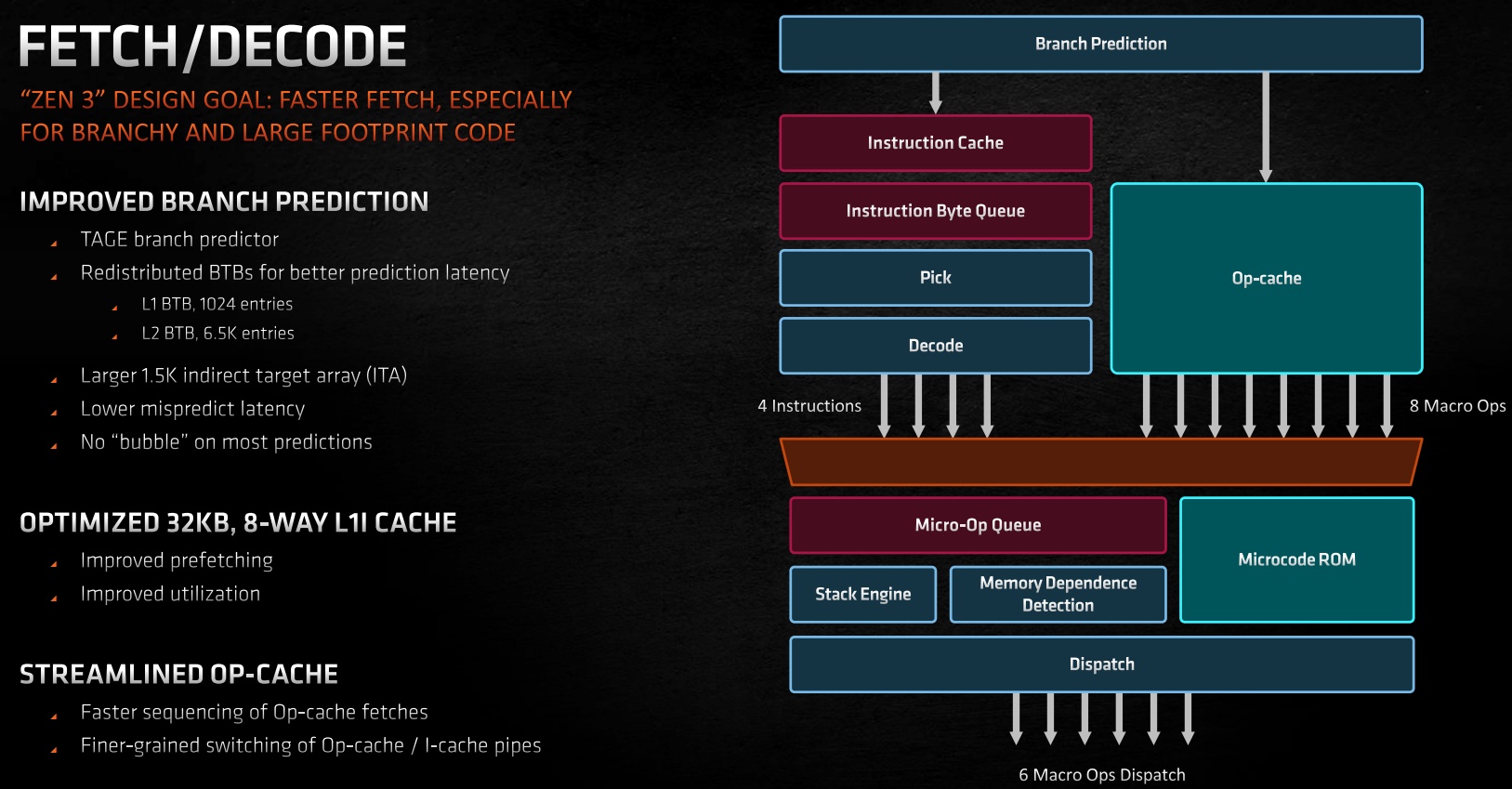
A Zen 3 mag az eredeti Zen radikális továbbfejlesztésének számít, és megörökölt majdnem minden képességet a párhuzamosan tervezett Zen 2-ből is. Utóbbihoz viszonyítva az egyik kritikus változás az elágazásbecslőt érte. A rendszer elvi működését tekintve nem változott, azaz maradt a TAGE (Tagged Geometry) megoldás, ami kiegészíti a hash perceptront az elágazások esetében. Utóbbi ellenőrzi az L1-et, míg előbbi az L2 branch target buffert (BTB). Ezek mérete ugyanakkor módosult, rendre 1024 és nagyjából 6500 bejegyzésre.
Az L2 branch target buffer esetében, a korábbi cikkek alapján feltűnhet, hogy a Zen 2-höz viszonyítva kevesebb bejegyzést tud tárolni a Zen 3, de ez az AMD szerint így is elég jó, mert közben a késleltetés javult. A közvetett elágazás detektálását továbbra is az ITA, vagyis az Indirect Target Array végzi, ennek nagyjából 1500 bejegyzési helyének egyikére kerül az elágazás. A Zen 3 az elágazásbecslés hatékonysága szempontjából hasonló értékeket tud felmutatni, mint a Zen 2, ami már így is elég jó volt, a mostani fejlesztések fő célját az adta, hogy az egész sokkal gyorsabban működjön, vagyis a becsléseknek jóval hamarabb legyen eredménye. Ezt az AMD "No Bubble" megoldásnak nevezi.
[+]
Az utasításbetöltés és dekódolás tekintetében a Zen 3 továbbra is egy 32 kB-os, nyolcutas, csoportasszociatív utasítás gyorsítótárat használ, de a Zen 2-höz viszonyítva javult a kihasználhatósága. Mindemellett az op-cache lényegesen hatékonyabban működik: gyorsabb szekvenálást kínál a betöltésekhez, illetve finomszemcsés váltást biztosít az op-cache és I-cache futószalagokon.
A Zen 3 mag a valós végrehajtás tekintetében továbbra is egy integer és egy lebegőpontos blokkra oszlik, de igen jelentősek a változások a korábbi fejlesztésekhez képest. A fő cél az volt, hogy csökkenjen a késleltetés, illetve javuljon az utasításszintű párhuzamosság.

[+]
Az integer rész alapját négy darab, egyenként 24 bejegyzéses ütemező adja, vagyis mostantól nem kap minden feldolgozó saját ütemezőt, csak a négy darab ALU (aritmetikai-logikai egység), és ezek mellé lesz párosítva egy-egy másik egység, ami lehet AGU (címgeneráló egység) vagy BRU (Branch Unit). Az új Zenben összességében egy BRU-val kombinált ALU, egy-egy St-data ALU és AGU, két-két normál ALU és AGU, valamint egy dedikált BRU található, miközben az LSU (Load/Store Unit) három loadot, illetve kettő store-t képes elvégezni ciklusonként. Ez a Zen 2-höz viszonyítva igencsak szálkásított rendszer, így a re-order buffer (ROB) és a fizikai regiszterek esetében 256, illetve 192 bejegyzésre kellett növelni a méretet, hogy az új konfiguráció hatékonyan működtethető legyen.

[+]
A lebegőpontos részt valamivel kevesebb változás éri, de az ütemezés itt is hatékonyabb lett. Természetesen megmarad a két darab 256 bites FMAC vektormotor, amelyek egy-egy 256 bites FMA operációt vagy egységenként egy 256 bites ADD és egy 256 bites MUL operációt tudnak elvégezni. Ami előrelépés, hogy egy órajelciklussal gyorsabb lett az FMAC operációk elvégzése, illetve az AMD két különálló, adatmozgásokat kezelő részegységet is beépített, ezekkel a valós feldolgozók némileg tehermentesíthetők.

[+]
A load/store képességek tekintetében a store 48-ról 64 bejegyzésre hízott, míg az L2 DTLB nagyjából 2000 bejegyzést tud tárolni. Az L1 adat gyorsítótár maradt 32 kB-os nyolcutas, csoportasszociatív.

 [+]
[+]
A Zen 3 a Zen 2-höz viszonyítva új utasításokat, illetve funkciót is bevezet. Egyrészt a VAES és a VPCLMULQD utasítások kiegészülnek az AVX2 támogatásával, így 256 bites operációkkal is alkalmazhatók, másrészt újdonság az MPK, amit szoftveres szinten támogatva biztonságosabbá tehetők a felhasználói adatokhoz való hozzáférések. Mindezeken túl lényeges még a CET, vagyis a Control-flow Enforcement Technology bevezetése, ami biztonsági mechanizmust kínál a ROP (Return Oriented Programming) támadások megakadályozására.

[+]
A fenti változásokkal az AMD jelentősen javított az IPC-n, vagyis az egy órajelciklus alatt elvégzett műveletek számán a Zen 2-höz viszonyítva, illetve az új gyorsítótárstruktúrával még a többszálú munkavégzés is hatékonyabb. A vállalat szerint az átlagos előrelépés 19%, de a változásokat a cég számos alkalmazásban kimérte, és 9-39% közötti tempónövekedés látható az egy évvel korábbi fejlesztéshez képest, méghozzá azonos órajelen.

[+]
Gyors energiatakarékosság
Az AMD, bár az energiatakarékosságra, illetve feszültség- és frekvenciaskálázásra vonatkozó technológiákon nem sokat változtatott, vagyis továbbra is lényegében ugyanaz a rendszer működik a Zen 3-ban, mint az előző generációs fejlesztésben, arra azért kitért, hogy a kialakított hardverük működése szoftveres szinten elemezve nagyrészt láthatatlan.
Ez egy visszatérő tényező szokott lenni a Ryzent már birtokló tulajdonosoknál, így a vállalat a mostani generációnál igyekezett kihangsúlyozni, hogy az alkalmazott Precision Boost 2 technológia meglehetősen gyorsan dönt arról, hogy az adott szituációra milyen órajelet és feszültséget állít be. Egészen konkrétan minden ezredmásodpercben változhatnak ezek a paraméterek, amelyeket végeredményben a lapkáról folyamatosan készülő és elemzés alatt álló, úgynevezett hőtérkép határoz meg. Nincsenek tehát előre kijelölt órajelszintek, nincs magonkénti maximum a turbóra, nincs fix időtartam az alapnál magasabb órajel alkalmazására. Mindenről a hardver dönt a környezeti hőmérsékletet is figyelembe véve.

[+]
Ilyen formában a Ryzen 5000 sorozat, illetve még a korábbi Ryzenek is képesek arra, hogy akár az összes magra beállítsanak egy maximális turbóhoz közeli órajelet, ami ugyan nagyon elméleti lehetőség, de technikailag megoldható. Az AMD viszont ezt a rendszert nem a pillanatnyi vagy a rövid ideig tartó turbó miatt fejlesztette, hanem pont a tartósan magas órajel érdekében. A működést tekintve a hardver két nagyobb működési módot alkalmaz. Amikor a felhasználó olyan programot futtat, ami csak egy szálat tud terhelni, akkor azt megkapja az adott processzor úgynevezett leggyorsabb magja. Ez minden egyes lapkán kijelölésre kerül, és ez akár még a maximális turbó fölé is képes menni, persze csak Precision Boost Overdrive-val. Ilyenkor a hardver azon dolgozik, hogy gyorsan végezzen a feladatokkal, és minél hamarabb visszakapcsolhasson energiatakarékos állapotba. Ugyanakkor ez osszabb távú terhelés mellett nem működik, mert idővel az adott mag úgyis túlmelegszik, vagyis csökkenteni kell az órajelet a hőmérséklet szinten tartása érdekében. A helyzet romlik többszálú feldolgozás mellett, és ilyenkor a hardver már arra koncetnrál, hogy a turbó lehetőségét minél tovább életben tartsa. Ez az AMD rendszerének legfőbb fegyvere, ugyanis nem fog fixen fél vagy egy percen belül leállni, hanem több, akár 3-5 percig is képes a turbó órajelet relatíve magasan tartani.
A kulcstényező itt az, hogy a processzor már nem igyekszik tartós terhelés mellett arra, hogy gyorsan végezzen a feladattal, hanem megpróbálja menedzselni a munkavégzést a magok között, és ehhez az AMD külön energiaprofilt is szállít a Windows 10-hez. Ez azért lényeges tényező, mert van már a Ryzenhez harmadik féltől származó, órajelmenedzsmentet módosító alkalmazás is, ami a gyárinál nagyobb teljesítményt ígér. Itt a kérdés az agresszivitás, ugyanis lehet arra optimalizálni, hogy a processzor az első pár percben nagyobb teljesítményre legyen képes, de akkor később már alacsonyabb órajelek kerülnek beállításra, ugyanakkor pár percnél hosszabb távra is dolgozhat a rendszermenedzsment.
A gyári konfigurációt a tartósságra paraméterezték, vagyis egy alternatív paraméterezéssel az első két-három percben el lehet érni nagyobb teljesítményt, de hosszabb távon vizsgálva már nem. Innentől ez már egy felhasználói választás, ha valaki mondjuk úgy futtat programokat, hogy két perc után bezárja, pihenteti a gépet pár percig, majd újra két percet dolgoztatja a rendszert, akkor előnyösebb lehet a harmadik féltől származó konfigurálás. Tartós, nagyjából öt-hét vagy több perces munkavégzésre viszont a gyári profil a jobb.
A probléma az egésszel az, hogy a motorháztető alatti működést nehéz mérni, mert a Ryzenek órajel- és feszültségváltása egyszerűen túl gyors. A legtöbb szoftver fél-egy másodpercenként vesz mintát, amit ki tudnak jelezni a felhasználók felé, így viszont két jelzett adat között nincs meg az temérdek, sok száz órajel- és feszültségváltásra vonatkozó információ, amit a hardver kvázi láthatatlanul elvégzett. Ezen próbál segíteni az AMD azzal, hogy a saját szoftverükben átlagos paraméterekkel dolgoznak, de a működésbeli ugrások igen nagyok is lehetnek, különösen enyhe terhelés mellett.
Ennél érdekesebb tényező a sleep state-ek helyzete. A szoftver oldaláról úgy tűnhet, hogy ezek nem igazán működnek a Ryzenen, de valójában nagyon is üzemelnek, hiszen az AMD az energiamenedzsmentet nem az órajel alacsonyra állításával éri el, hanem a nem használt magok alvó állapotba helyezésével. Ezek valójában tehát megtörténnek, csak az operációs rendszer nem biztos, hogy látja.

[+]
Az AMD egy példát is kimért, ami egy processzor ötödik magjának 1 másodpercig tartó aktivitását mutatja. Látható a képen, hogy 250 ezredmásodpercenként mért mintával 5 különálló eredmény lesz, ami elég jónak tűnik egy ember számára, csak közben a hardverben megkülönböztetett 995 állapotról nincs adat. Ráadásul azzal sem lennénk kisegítve, ha ezeket valahogy ki lehetne olvasni valós időben, mivel nincs olyan monitor a piacon, ami elég gyorsan frissít ahhoz, hogy mindegyik információt megjelenítse.

[+]
A Ryzen működése során igyekszik a terhelésmentes időszakokban a C6-os, vagyis a legmélyebb sleep state-be kapcsolni. Ennek prózai az oka: ez a leginkább energiatakarékos megoldás. Ha a fenti példát kinagyítjuk, akkor látható, hogy az 1 másodperces időintervallumban igen sokszor aktív volt a C6-os állapot, vagyis a mag konkrétan lekapcsolt, miközben az operációs rendszer azt mutatta, hogy ez nem történt meg. Ez valójában azt az illúziót kelti, hogy C6-os állapot nem működött, ezzel szemben a valóság az, hogy a mag a mért időtartamon belül az elkülönülő állapotok 33%-át ezen a szinten töltötte.
Az AMD szerint a problémára a megoldás a szoftverek fejlesztése, ezek ugyanis az elavult feszültségskálázási rendszerekhez igazodnak még ma is, ahol jó eredményt tudnak kimérni, de a Ryzenhez hasonló, modernebb rendszereknél ez nagyon kevés. Elérhető azonban a Ryzen Master SDK, amivel a fejlesztők be tudják építeni a mérőprogramokban az átlagos feszültség közlését. Ezzel ugyan a pillanatnyi állapotról nem kap képet a felhasználó, de legalább nem marad észrevétlen az állapotváltások 99%-a.
Nem mellesleg az AMD megjegyezte, hogy ha a C6-os állapotot nem tudnák működtetni, akkor megközelítőleg sem lehetne olyan jó teljesítmény/fogyasztásra vonatkozó adatokat felmutatni, amiket egyébként a gyakorlatban kimérnek a tesztek, a Ryzen ugyanis ennek az állapotnak a folyamatos beállításától működik igazán hatékonyan.
CPU-k és alaplapok
A bejelentett, Ryzen 5000-es termékskála 6-, 8-, 12- és 16-magos modellekkel érkezik, a felhozatal paramétereit pedig az alábbi táblázat részletezi.
| Típus | Mag-/turbo órajel | SMT | L2 cache | L3 cache | Fogyasztás (TDP) | Listaár (dollár) |
|---|---|---|---|---|---|---|
| 9 5950X (16 mag) | 3,4/4,9 GHz | van | 16 x 512 kB | 64 MB | 105 W | 799 |
| 9 5900X (12 mag) | 3,7/4,8 GHz | van | 12 x 512 kB | 64 MB | 105 W | 549 |
| 7 5800X (8 mag) | 3,8/4,7 GHz | van | 8 x 512 kB | 32 MB | 105 W | 449 |
| 5 5600X (6 mag) | 3,7/4,6 GHz | van | 6 x 512 kB | 32 MB | 65 W | 299 |
Az új processzorok hivatalosan a 3200 MHz-es, JEDEC szabvány szerinti DDR4-es modulokat támogatják, természetesen kétcsatornás módban. Érdemes még észben tartani, hogy gyári hűtő (Wraith Stealth) csak a Ryzen 5 5600X-hez lesz.

[+]
Az alaplapokból az 500-as sorozatú vezérlőhidakat ajánlja az AMD. A Ryzen 5000 használatához olyan BIOS kell, ami legalább az 1.0.8.0-s AGESA-t alkalmazza, de már elérhető a gyártóknak az 1.1.0.0-s verzió, amire érdemes lesz frissíteni. A 400-as sorozatú alaplapok esetében az AMD megígérte a támogatást, és ezt az ígéretüket meg is tartják. A szükséges AGESA fejlesztés alatt áll, és a cég közleménye szerint a következő év januárjától adják majd ki a megfelelő béta BIOS-okat az alaplapgyártók. Ha a vásárló esetleg úgy vett új generációs Ryzent, hogy nem frissítette a BIOS-t a megfelelő verzióra, akkor továbbra is lehet kérni Boot Kitet.
A Ryzen 5000 sorozat az 500-as sorozatú, ezen belül is B550-es és X570-es vezérlőhidak mellett támogatni fogja a Radeon RX 6000-es termékcsaláddal elérhető Smart Access Memory funkciót, amiről az alábbi hírben írtunk bővebben. Bár ez szorosan nem tartozik a processzorhoz, de az AMD már platformszinten dolgozik, így a termékeik együtt többre képesek, mint külön-külön, és a cég szerint ez egy olyan irány, amit a jövőben erősebben meg szeretnének lovagolni.
Az elméletet a gyakorlatban egy későbbi tesztben fogjuk megnézni, de az előzetes adatok alapján a Zen 3-mal az AMD komoly erőt fog képviselni a piacon.
Abu85



















