
- ThinkPad (NEM IdeaPad)
- Milyen billentyűzetet vegyek?
- Milyen TV-t vegyek?
- LCD, plazma és projektoros TV-k hibái
- AMD Ryzen 9 / 7 / 5 / 3 5***(X) "Zen 3" (AM4)
- Gaming notebook topik
- Azonnali fotós kérdések órája
- Projektor topic
- AMD Radeon™ RX 470 / 480 és RX 570 / 580 / 590
- Megérkezett a legújabb és eddigi legátfogóbb 3DMark teszt
Hirdetés
-


Ilyen lehet a Samsung Galaxy Watch7 Ultra
ma Renderképek mutatják meg a Samsung júliusban megjelenő új felső kategóriás okosóráját.
-


Békésen legelészik a májusi hardvercsorda
ph Ezúttal monitorokat, processzorhűtőt, házat, routert, tápokat, egérpadot és akciókat tereltünk be a szombati karámba.
-


Spyra: nagynyomású, akkus, automata vízipuska
lo Type-C port, egy töltéssel 2200 lövés, több, mint 2 kg-os súly, automata víz felszívás... Start the epic! :)






Új hozzászólás Aktív témák
-

dezz
nagyúr
A HSA részben éppen arról szól, hogy az egészet megreformálják és a GPU-t beemelik a CPU(+FPU)+MMU kis közösségébe. Légy üdvözölve egy új galaxisban (itt még FSA-ként hivatkoztak rá):
The Programmer's Guide to the APU Galaxy
Plusz vess 1-2 pillantást ennek a cikknek a végén lévő két slide-ra.
"vélemény: nem kell gpgpu. egy erős, sok magos, jó processzor kell, ami el tudja látni a gpu feladatát is."
Na persze, 10x akkora szilícium területtel és 100x akkora fogyasztással... (Már ha egy chipen megvalósítható lenne, de nem lehet a hőtermelés miatt.)
-

ddekany
veterán
Én úgy értettem az itt a cél (hosszú távon), hogy a GPU-s kód is ugyan abban a címtér + privilegitási szint fusson, mint az alkalmazás CPU-s kódja. Te meg lényegében azt mondod, hogy na ja, csak ezt büdös életben meg nem oldják, csak hülyítik a népet ezzel az ígérettel? Én ezt végül is nem tudhatom, mert a GPU-k lelki világát nem ismerem. De konkrétan miért lenne ezt lehetetlen megoldani, hogy a GPU is beilleszkedjen ebbe a rendszerbe? (Ettől persze még lehet, hogy mondjuk a mostani DirectX/OpenGL cuccok külön címtérben futnak, meg főleg, másolgatnak, hogy ne hányják össze egymás adatstruktúráit a hagyományos alkalmazással.)
-

P.H.
senior tag
A 256 bites lebegőpontos végrehajtók NEM 256 bites számokon dolgoznak, hanem egymást követő 8 db 32 bites vagy 4 db 64 bites számon (=vektor). Ilyenek már a Sandy és Ivy Bridge-ben is vannak, itt most csak átszervezték őket (+FMA), a nagyobb újdonság az, hogy az integer (fixpontos) ALU-k is 256 bitesek lettek; ezek eddig 128 bitesek voltak, így képesek egyszerre 32 byte-on, 16 word-ön, 8 duplaszón vagy 4 db 64 bites értéken dolgozni.
A SIMD nem egymást követő utasítások kötegelésére való, hanem egymást követő adatokéra; ez is a neve: Single Instruction Multiple Data (képes olvasnivaló még az AVX1-ről).A Haswell-ben mind fixpontos, mind lebegőpontos 256 bites végrehajtóból 3-3 van, utóbbiból 2 képes az FMA-műveletekre, továbbá az egyik az osztásra/szorzásra, a másik összeadásra/kivonásra/összehasonlításra, a 3. csak a vektorelemek átrendezésére.
A késleltetés nem valami kényszeredett várakozás, hanem az utasítás végrehajtásának ideje (az angol latency szó tükörfordítása lappangás), ennyi idő alatt van készen egy művelet. Minden utasításnak - a legegyszerűbbnek is, mint két egész szám összeadása - legalább 1 ciklus a késleltetése, a lebegőpontos számok műveletei tovább tartanak:
Core2/Nehalem/Sandy/Ivy/Haswell: az összeadás 3, a szorzás 5 órajel
Bulldozer: összeadás és szorzás is 5-6 órajel
K10: összeadás és szorzás is 4 órajel (példa; L=latency T=throughput)
Az, hogy "pont 5-tel több, mint kellene" olyan, mint számonkérni egy 12 ms elérési idejű HDD-n, hogy ez pont 12-vel több, mint amennyinek kéne lennie; vagy legyen 1 ms, különben semmit se ér Nagyon szakmai...A gather-utasítások memóriaolvasó utasítások, paraméterben kapják meg, hogy milyen címekről olvassanak, majd ezeket az értékeket megfelelően sorba állítva egy vektort képeznek. Semmi közük a műveletekhez, a TMU-hoz, sem "bedrótozva" nincs beléjük a címek távolsága.
Sosem láttam még olyan hozzászólást, ami 100%-ban szakmaian hangzó köntösbe (köntös... bikini) bújtatott halandzsa.
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
Tehát minimum 5; (mennyi a maximum? mikor ennyi? amikor előtte össze kell kapnia magát a CPU-nak?) és legyen minimum 0 vagy 1. A Cell FMA-ja minimum 6 órajel, még rosszabb?
Kérlek mondj olyan utasítást, amely 128 vagy 256 bites lebegőpontos számokkal dolgozik; vagy innen olyan adattípust!
Nem, nem ez a SIMD lényege, (az a CISC-be hajló bonyolultabb utasításoké, pl. POPCNT, PCLMULQDQ), hanem hogy n elemű tömb(ök)re ugyanannyi műveletből álló for-jellegű ciklus n helyett - adattípustól függően - csak n/2, n/4, ..., n/32 alkalommal fusson le, vagy ne is kelljen ciklus egyáltalán; így a CPU által végrehajtott utasítások száma feleződik, negyedőlik, ..., 32-edelődik, vagy 1-re csökken (maga a for is jópár utasítás).
Mutatsz ebben az AIDA-mérésben olyan utasítást, amely 0 órajel alatt fut le? Ezt mondja az AMD ugyanerre (Appendix C Instruction Latencies).
Regiszterek ide-oda másolgatásából vagy nullázásából nemigen lehet programot írni.Adhatsz linkeket, hivatkozásokat bőven, gondolom, nem magadtól találod ki ezeket.
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
A 40 órajeles tipped mire alapozod?
Azt, hogy a long double 128 bites, mire alapozod?
Az FMA nem SIMD, csak egy művelet, mint az összeadás vagy az osztás: van skalár formája (pl. VFMADDSS), ami csak 1 számpárt szoroz össze és hozzáad egy harmadikat, és van SIMD formája (pl. VFMADDPS), ami több számpárt szoroz össze egyszerre, majd a eredményekhez hozzáad egy-egy harmadik számot, így több eredmény lesz ugyanannyi idő alatt.
Mint írtam a végén, bármit linkelhetsz, nem kell az én linkjeimre hagyatkozni.
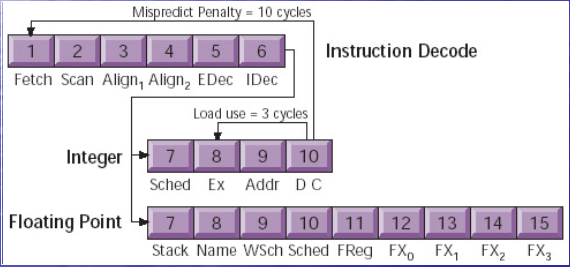
A kép egy pipelined execution unit végrehajtás-idődiagramja, amely fél órajelenként 1 utasítást küld tovább (double-pumped); nincs ebben semmi szokatlan vagy érdekes (csak nem érted, mi van rajta): a gyártók által megadott latency-k az Execute lépcsőre vonatkoznak (az állhat utasítástól függően változó számú lépcsőből*), az meg lemaradt az ábráról; már csak ott kapcsolódunk be, hogy a lefutás után kiírja az eredményt (Data1/Data2/Tag Ch./Write).
*itt a K7 (Athlon XP, Barton pl.) pipeline-ja:
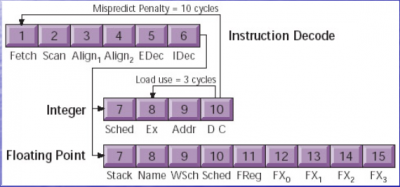
Az integer (egész számos SISD) utasításoknak egyetlen lépcsője van (Ex) a Sched (=ütemezés után; az Addr és DC lépcső a cache-hozzáféréshez kell csak), le is fut mind 1 órajel alatt, a lebegőpontos számoknak 5 (FReg, FX0-FX3); viszont tudjuk a gyártói információkból és a mérésekból, hogy nem mindegyiknek kell végigmennie mind a 5-en, van, amely 2 órajel alatt eredményt ad. A write-back lépcsői ezen nincsenek rajta, mivel nem szükségesek a következő függő utasítás indításához.
Ezen (Atom pipeline) viszont rajta vannak (itt pedig a több EX-lépcső nem szerepel, pedig van):

[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
Sejtettem: a sizeof(long double) csak játék a fordító részéről (align miatt), 128 bitet foglal le neki, de az adattartalom csupán 80 bit. Ilyesmit már a 90-es évek óta csinálnak a fordítók.
Szerinted mindegy, amúgy nem, nincs helye "is" szónak, a SIMD nem arra való.
RSQRTF nincs az x86-on, az nVidiánál van CUDA-ban.
A VLIW megint teljesen más.Az 2-3-4-whatever ugye vicc?. Ezek gépek, terv szerint működnek, minden előre tudható (már csak azért is, mert le kell teszteni, validálni a CPU-t). Valamint egy processzor két dologra jó: kitenni egy vitrinbe, ha már elég öreg, illetve programokat futtatni rajta; mindkét esetben mi értelme lenne elhallgatnia a gyártónak, hogy mi az adott CPU-n a legjobb programok, az optimalizáció és végső soron a működésének titka? Üzleti érdeke is, hogy az övén fussanak leggyorsabban a programok, amit mások csinálnak.
Ha írnál kézzel assembly kódot, akkor tudnád, hogy a megadott értékek igazak; úgy, hogy közted van egy fordító vagy egy/több köztesréteg, elveszett a talaj, a számokra nem alapozhatsz. De attól még azok a számok igazak maradnak, csak már nem tapasztalhatóak a valóságban, mert nem tudod, mi (és a fordító által mennyivel több minden) is történik valójában, mint amit akartál.
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
P.H.
senior tag
#109: ?
#108: nem, a SIMD az az RSQRTPS.
Nem találom, hol mondtam ezeket.
Semelyik linkben nem látok RSQRTF-et, csak RSQRTSS-t: közelítő négyzetgyököt számol egyetlen 32 bites lebegőpontos számra (skalár, a SIMD párja az RSQRTPS).
Erre gondoltál: [link]
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
dezz
nagyúr
Vagy 20 vagy akármennyi. Megint a hasadra ütöttél... Különben sem az számít, hogy a teljes kód mekkora része SIMD, hanem hogy a futásidő mekkora részét teszi ki, illetve mennyivel gyorsítja a műveletet. Egyébként pedig a kérdésben benne volt, hogy jól párhuzamosítható. (Más kérdés, hogy van egy ésszerű határa a SIMD szélesítésének, lévén egy valós kód nem csak alap- és egyéb számítási műveletekből áll.)
[ Szerkesztve ]
-
dezz
nagyúr
Senki sem mondta, hogy a SIMD-esítés (és párhuzamosítás) a legkényelmesebb programozási forma... Az adatstruktúrát célszerű előre eltervezni. Ennek jelentősége nyilván attól is függ, hogy mennyit is kell "tökölni" a procin belül az adatokkal. Ha jó sokat nem túl sok adattal, akkor a műveletek előtti átrendezés is bőven beleférhet.
(#129) ddekany: Valószínűsíthető. Plusz a meglévő kódbázis viszonylag egyszerű alkalmazhatóságát is próbálják komoly versenyelőnnyé alakítani. Ez nyilván kevésbé hatékony, mint mondjuk egy jól megírt HSA kód, de ezt a gyártástechnológiai előnyükkel és erre építve az egyre több maggal próbálják majd ellensúlyozni (bár ez egyre kevésbé működik, ahogy lassan fő tényezővé válik az energiahatékonyság), emellett az üzleti befolyásukat is latba vetik.
-
dezz
nagyúr
Lehet, de ennél fontosabb, hogy azok azért használgatják, akik olyan programokat írnak, ahol ennek különösebb jelentősége van. Ezeket a teljesítményigényesebb, spécibb programokat nem kezdő/harmadrangú programozók írták általában.
Visszatérve a GPGPU-ra, ami ellen először megszólaltál, nos ott pl. az OpenCL elég jó kompromisszum a hw-közeli programozástól való mentesség és a jó teljesítmény között. A HSA pedig a hatékonyságnövelés és a lehetőségek kiterjesztése mellett nem kicsit egyszerűsíti tovább az egészet.
Az Intel - mivel nagyteljesítményű GPU fejlesztésben nincs túl sok tapasztalatuk - is azzal próbálkozik már évek óta (eleddig nem sok sikerrel), hogy alaposan leegyszerűsített, ugyanakkor széles SIMD feldolgozással bíró magokból pakol többtízet egymás mellé. (Később állítólag az mai IGP-jük helyét is ilyen komplexum fogja átvenni a hibrid chipekben, a néhány hagyományos CPU mag mellett.)
Már elhangzott, miért elkerülhetetlen mindez: a sima CPU magoknak sokkal rosszabb az energiahatékonysága (telj./watt). Ez ott válik kritikussá, hogy hiába csökkentik a csíkszélességet, a fogyasztás nem csökken a kellő arányban ahhoz, hogy a teljes chipterületet ilyen magokkal szórhassák be.







Új hozzászólás Aktív témák

ph Az új generációs architektúra lényegében az IGP szempontjából fejlődött, de az AVX2 utasításkészlet is hasznos.
- ThinkPad (NEM IdeaPad)
- Milyen billentyűzetet vegyek?
- Samsung Galaxy S23 Ultra - non plus ultra
- Milyen TV-t vegyek?
- Luck Dragon: Asszociációs játék. :)
- Vicces képek
- LCD, plazma és projektoros TV-k hibái
- Milyen légkondit a lakásba?
- bambano: Bambanő háza tája
- Debrecen és környéke adok-veszek-beszélgetek
- További aktív témák...

- Beszámítás! Intel Core i7 4790 4mag 8szál processzor garanciával hibátlan működéssel
- intel LGA1200 Processzorok i3 / i5 / i7 / i9 - Új - Garanciás
- Eladó Intel Core i5 4440 / i3 4130 / Pentium G4400, G4600 processzor garanciával hibátlan működéssel
- Beszámítás! Intel Core i9 11900KF 8mag 16szál processzor garanciával hibátlan működéssel
- Intel I7 12700KF 14mag/20szál - Új, Tesztelt - Eladó! 85.000.-
Állásajánlatok

Cég: Alpha Laptopszerviz Kft.
Város: Pécs

Cég: Promenade Publishing House Kft.
Város: Budapest