
- Megérkezett Magyarországra az LG 480 Hz-es OLED monitora
- Computex 2024: feltárta a Lunar Lake-et az Intel
- Kormányok / autós szimulátorok topicja
- Vezetékes FEJhallgatók
- AMD Ryzen 9 / 7 / 5 7***(X) "Zen 4" (AM5)
- Apple notebookok
- Ventilátorok - Ház, CPU (borda, radiátor), VGA
- E-book olvasók
- Autós kamerák
- AMD K6-III, és minden ami RETRO - Oldschool tuning
Hirdetés
-


Computex 2024: a CEO az új rocksztár
ph A nagy technológiai cégek vezetőit film- és rocksztárokat idéző rajongással veszik körül itt.
-


Olajkereskedelem dollár helyett CBDC-ben?
it Szaúd-Arábia is csatlakozott a Nemzetközi Fizetések Bankja és Kína által vezetett jegybanki digitális pénzes projekthez, ami nagy változásokat hozhat.
-


Az iPhone 15 frissítésgaranciát, a 16 szép rendereket kapott
ma Sokáig hallgatott az Apple a frissítésekről, most viszont megtudtuk, mennyit garantál.






Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
A hardver elméleti képességeiről beszéltem. Szoftverben még mindig fényévekre vannak. Amiről 'Geri' ír az az OpenGL driver, ami tényleg rém gyenge az Intelnél.
A hardver tempóját tekintve persze jóval lassabb a HD Graphics 4000, mint a leggyorsabb Trinity-s Radeon IGP (akár mobil, akár asztali), és ez főleg akkor jön elő, ha magas részletességet állít be a user a programnak, ahol a HD 4000 elfogy. Jellemzően médium szintig bírja. Ezek nyilván abból erednek, hogy az AMD jóval erősebb setup részt használ, hiszen órajelenként feldolgoz egy háromszöget, ami az Intelnek négy órajel, vagy a textúrázóblokk az valóban képes Gather4-et használni, ami pokoli előny DX10./11 alatt, hiszen minden ilyen játék támogatja. Az Intel tök logikátlanul csinálja, mert egy csatornán csak egy mintavételező van, míg az AMD-nél egy csatornához négy tartozik. A Gather4 utasítás az logikus. Egy helyet egyszerre négy mintavétel legyen, ehhez négy mintavételező kell, ahogy az AMD csinálja. Az Intel megoldása formálisan képes támogatni, de úgy, hogy négy órajelig csak a mintavételezéssel törődik az adott textúrázó csatorna. Ez a megoldás még lassabb is lehet, mint Gather4 nélkül, hiszen 3 kötelező üres ciklust fut a szűrő és a címző. Bárki találta ezt ki az Intelnél, az remélhetőleg már nem dolgozik ott (a jövőre való tekintettel persze, semmi személyes
 ). Szerencsére a Haswell IGP-je már valós Gather4 támogatást kap. A kisebb-nagyobb gyenge pontok mellett azért a Gen7 architektúra már elég jó. Gyakorlatilag a Gather4 para az egyetlen, ami komoly gond. Persze az LLC-be mentő stream out sem a legjobb, de az még benne van az elfogadható kategóriában. Ami viszont elég jó az a compute hatékonyság, és ez első nekifutásra dicséretes. Ha igazak a feldolgozók számáról érkező pletykák, akkor ez a Haswellben is javulni fog valamennyit. Persze a GCN ellen kell is.
). Szerencsére a Haswell IGP-je már valós Gather4 támogatást kap. A kisebb-nagyobb gyenge pontok mellett azért a Gen7 architektúra már elég jó. Gyakorlatilag a Gather4 para az egyetlen, ami komoly gond. Persze az LLC-be mentő stream out sem a legjobb, de az még benne van az elfogadható kategóriában. Ami viszont elég jó az a compute hatékonyság, és ez első nekifutásra dicséretes. Ha igazak a feldolgozók számáról érkező pletykák, akkor ez a Haswellben is javulni fog valamennyit. Persze a GCN ellen kell is.
Összességében a Gen7 architektúra tényleg nem rossz. Ami jelentősen visszafogja bizonyos szituációkban az a driver, és erre az Intel még mindig nem fordít kellő figyelmet.A WinZip és a VLC egy vitában merült fel. Nem azért, mert a legjobb példák az elérhető gyorsulásra, hanem azért, mert csak AMD-s OpenCL driverrel működő funkciókat tartalmaznak. Ez úgy jön le, hogy az AMD kisajátít egy szabványt, de valójában csak a fejlesztők nem engedik, hogy fusson a funkció Intel és NV driveren, amíg nem tudják garantálni a sebességelőnyt, vagy a megfelelő működést.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

#95904256
törölt tag
Valóban szórakoztató.
Pongyolán foglamaz, rengeteget személyeskedik és egy csomó mindenről halvány lila fogalma sincs, csak dobálózik velük. A "szakmai halandzsa" találó. Pl. "...a gyökvonást és az osztást kötegeli egybe...". A mögötte lévő összefüggések, itt pl. az, hogy a gyökvonás reciprokát kiszámító algoritmus sokkal gyorsabb iterál, teljesen lényegtelen a számára. Szó sincs semmiféle kötegelésről, egyszerűen hamarabb ad eredményt.
-

P.H.
senior tag
#110 és #111: Ez csak szórakozás volt, sikerült kihozni megint az igazi 'Geri'-t.
ON:
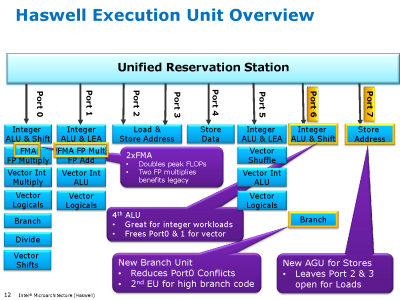
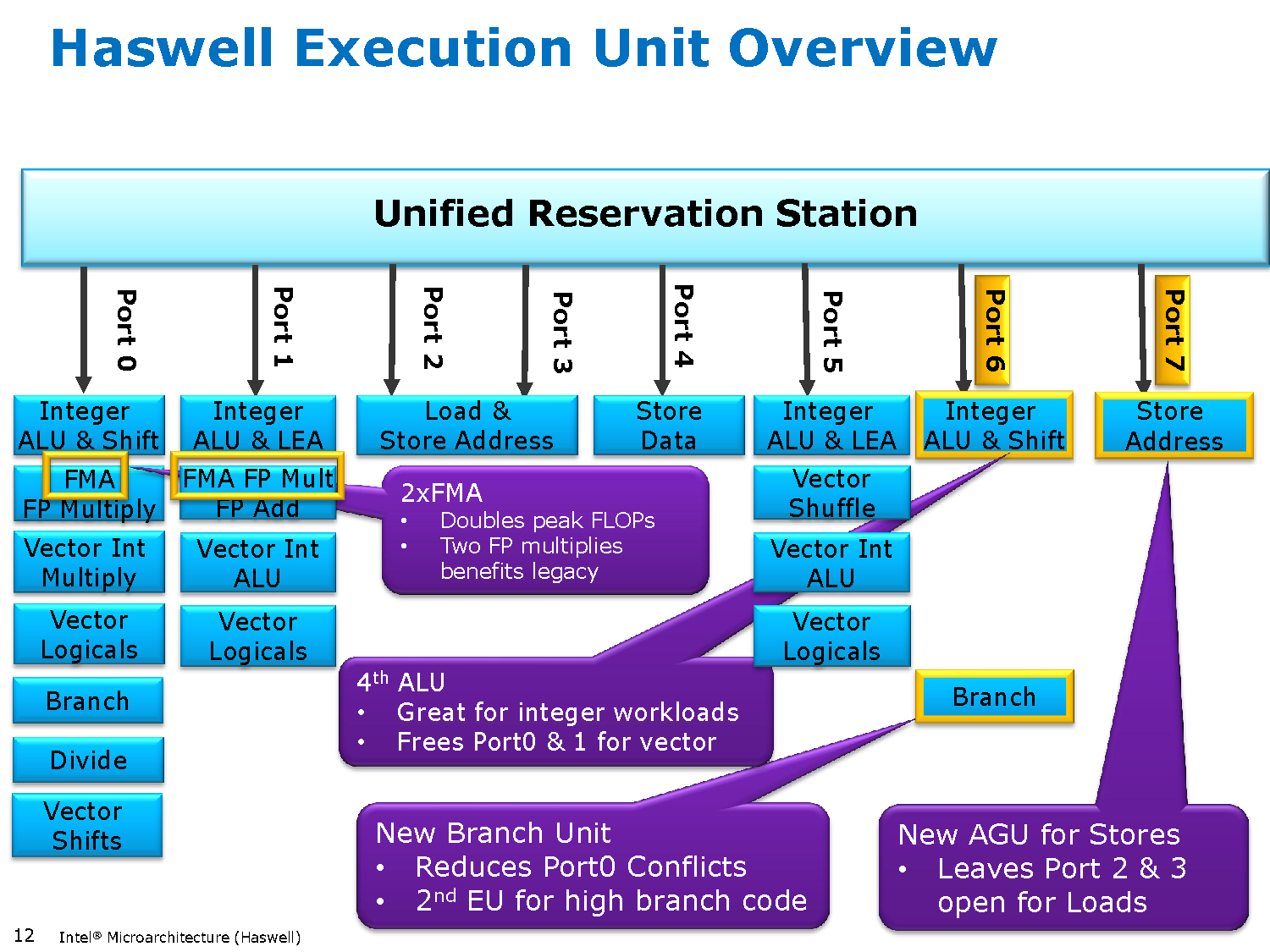
Ez egy igazi tock lesz (kívülről nem nagyon látható, de teljesen átdolgozott belsővel): a Core2 kapott utoljára plusz végrehajtó egységeket és az FMA 5 órajeles késleltetése (ami megegyezik az egyszerű szorzás időigényével) azt sejteti, hogy a belső RISC műveletek mostmár tényleg 2 helyett 3 forrásregiszterrel bírnak (eddig 2 volt, minden jel szerint PPro óta, tehát ez egy elég radikális váltás), mint eddig az AMD-ké.
Ez náluk egy új út kezdete, mint kb. a Bulldozer. Az AVX kimondottan ki lesz bővítve az Intel-nél hamarosan 512 illetve 1024 bitre (nem az IPG veszi át ezt a szerepet), csodálnám, ha az AMD közvetlenül követné 1024 bitre őket; ezzel látható, mivel akar versenyezni az Intel.[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
-
P.H.
senior tag
Ez több szempontból is nehéz kérdés:
- egyrészt azért, mert nem vagyok jós
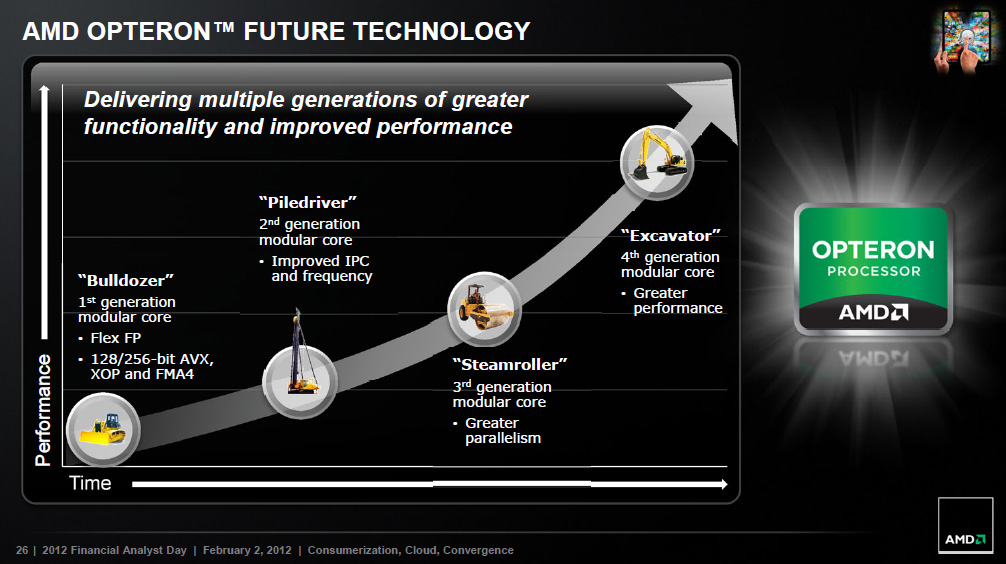
- másrészt azért, mert ez az ábra valószínűleg nem véletlenül zárul az Excavator-ral
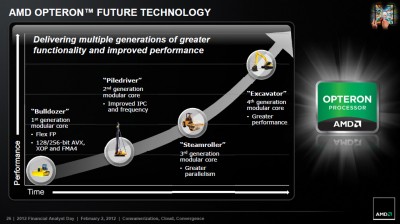
A Bulldozer-vonallal és ezzel a képpel úgy vagyok, mintha az Intel fejlődése lenne felgyorsítva:
+ Bulldozer = Pentium Pro: az alap, elsősorban szerver-orientált; egyik sem váltotta meg a desktop-világot
+ Piledriver = Pentium 2/3: elsősorban órajel-fejlesztések (ha nem is akkora boost, mint a Coppermine volt), mobil területre betörés
+ Steamroller = Pentium M: az egyik legnagyobb kerékkötő, a decode látványos fejlesztése (Intelnél a micro-fusion volt ez), ezzel igen hatékony mobil alternatívává tétele
+ Feltételesen a folytatás: Excavator = Core2? Ha behozzák végre az AGLU-kat, akkor nagyot erősödik az utasításvégrehajtás (~ a szélesség), beérne végre a teljes vonal.- harmadrészt ezt az ábrát nézve

nem biztos, hogy az FPU lesz lecserélve GCN-re; inkább egy-egy teljes modult válhat ki egy-egy CU. Egy 16 Kb 4-utas write-through L1D-vel és 16 utas L2-vel felszerelt CU-t GLC=1 állásban nem tud semmilyen más egység kívülről megkülönböztetni egy CPU-modultól és a CU-k a jelenlegi 512 bites vektor-egység mellett (a GPU-khoz képest) jól fejlett - és eléggé x86-közeli - skalár/fixpontos/integer egységgel is fel vannak szerelve.
Ha az Intel majdan egy gyűrűre felfűz néhány CPU-mag mellé pár Larrabee-magot (amik mindegyike x86-alapú), akkor az AMD miért ne tenné meg ugyanezt a felfűzést (a HSA-ra mint vISA-ra alapozva) néhány CPU-modul + tetszőleges számú CU felállásban?[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
Abu85
HÁZIGAZDA
Két részre kell bontani a kérdést. El lehet érni így is a megfelelő throughput teljesítményt ilyen homogén iránnyal, de csak akkor, ha a fogyasztást másodlagos tényezőként kezelik (szerverekben tolják is ki a TDP limiteket már a következő generációnál). Ha a mobil irányt ide vesszük, akkor egységnyi fogyasztás mellett semmi esélye olyan throughputot elérnie egy ilyen rendszernek, amilyenekkel az IGP-k dolgoznak. A felét talán lehet hozni, de akkor is az Intel homogén megvalósításának lesz a legnagyobb fogyasztása, beleszámolva két node előnyt (persze a Dennard Scaling hanyatlásával ez egyre kevesebbet ér). Ez a koncepció akkor érne valamit, ha az NTV technológiák már most bevethetők lennének, de egyelőre még kísérleti fázisban van.
Az AVX-1024-re inkább logikai szempontok szerint lenne érdemes gondolni. Már 512 bitre ki van terjesztve a Larrabee-ben. A következő lépcső az 1024 bit. Na most nem kötelező ám 1024 bites AVX utasításokat ilyen széles feldolgozókon végrehajtani. Lehet akár 256 biteseken is. Az látszik a Larrabee-n, hogy az Intel Pollack szabályát veszi figyelembe, ami ugyanolyan gyógyír a Dennard Scaling hanyatlására, mint a GPGPU.
Az Intelnek a rendszerszintű integrációja az olyasmi lehet, hogy megvan a gyűrűs busz alapnak, amire ott az LLC. A tárat le kell cserélni egy SRAM-nál jobb sűrűséget adó megoldásra. eDRAM is jó, ha az FBC nem jön be. A lapkában meg lesznek a magokhoz való szeletek, a gyűrűs busz, és azokra fel lesz fűzve x CPU-mag és "jóval több mint x" Larrabee mag. A Larrabee Pollack szabályára építkezik, míg a CPU-magokat meg kell tartani az értékelhető egyszálú teljesítményért. Az AVX támogatást egységesíteni lehet a két mag között, vagyis a Larrabee kaphat 1024 bites feldolgozókat, míg a CPU-magok képesek lehetnek 256 bites feldolgozókkal dolgozni, de ugyanúgy támogathatók az 1024 bites utasítások. És persze a CPU-magok más órajelen kell, hogy fussanak, mint a Larrabee magok, de ez a legegyszerűbb gond amit meg kell oldani a koncepcióban. Én ezt raknám össze, hogy versenyképes maradjak. Nyilván sok a buktatója, és sok a kockázat is, de most ezt fel kell vállalni.A HSA-t szerintem mindenképpen támogatni kell. Vagy, ha azt nem, akkor egy másik hasonló koncepciót. A fejlesztői nyomás itt most óriási lett, ahogy az AMD megmutatta mit tud egy ilyen rendszer. Johan Andersson már kiállt, hogy nem pont a HSA érdekli, hanem az a koncepció, amit az infrastruktúra felkínál a fejlesztőknek. Szerinte ez a jövő, és felszólította az összes gyártót, hogy álljon be mögé, vagy ha nem, akkor egyezzenek meg egy másik hasonló megoldásról, amit tényleg mindenki támogat. Erre egyébként az Intel kivételével szerintem mindenki hajlandó lenne, hiszen ellenérvet nehéz felhozni ellene. Az Intelnek az a baja, hogy a HSA, vagy a HSA-hoz hasonló koncepcióval teljesen bukó a felépített monopóliumuk. Gyakorlatilag az x86 mint jelenlegi erős érték szart sem fog érni.
A HSA azért opció, mert annak már kész van az 1.0-s draft specifikációja, és az úgy van kialakítva, hogy könnyű legyen támogatni a hardver oldaláról. Emellett a HSA-nál nyíltabb alternatíva aligha lesz. Minden alapító besorolású tag egységes anyagi támogatást ad, egységes a szavazati jog, egységes a beleszólás, egységes a marketing, szóval akár csinálnak mellé még egy másik alternatívát ennél egységesebb formai működést az sem tud majd felmutatni.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

Pikari
addikt
mert a hasamra ütöttem. és gyaníthatólag még mindig közelebb van a valósághoz, mint neked akármilyen más hosszas számításod lenne

azt még azért tegyük hozzá annak, aki még nem látott ilyet, hogy az adott művelet elvégzéséhez szűkséges adatok memóriában és kódban lévő reprezentációja általában nem is teszi lehetővé azt, hogy közvetlenül SIMD utasításokkal lehessen őket bojgatni, hanem át kell másolgatni őket. így sokszor az is előfordul, hogy amit az ember nyer a vámon, azt elbukja a postán.
[ Szerkesztve ]
A Dunning−Kruger-hatás az a pszichológiai jelenség, amikor korlátozott tudású, kompetenciájú vagy képességű emberek rendkívül hozzáértőnek tartják magukat valamiben, amiben nyilvánvalóan nem azok.
-
Pikari
addikt
ez egy kicsit erős kifejezés, hogy hülye lenne. a coder általában igyekszik olyan jellegű kódstruktúrát kialakítani, ami kényelmesen kezelhető, algoritmikailag könnyen átlátható, ebbe csak úgy simán nem vághatsz bele egy SIMD utasítást kézzel, ennek számos oka lehet, például hogy nem is úgy következnek a feladatok az algoritmusban egymás után, hogy triviálisan, ránézésre lehessen SIMD-et használni, a másik pedig, hogy az adatok nem megfelelően alignáltak (mert miért lennének azok).ha az ember SIMD-et akar a szoftverben, akkor azt bizony úgy kell szó szerint belefosni, (persze tekintsünk el ezesetben a fordítóprogram autómatikus SIMDesítésétől, ami általában - pont ugyanezen okok miatt - szintén nem is túl hatékony)
A Dunning−Kruger-hatás az a pszichológiai jelenség, amikor korlátozott tudású, kompetenciájú vagy képességű emberek rendkívül hozzáértőnek tartják magukat valamiben, amiben nyilvánvalóan nem azok.
-

ddekany
veterán
"A Larrabee alapú megoldás valószínűleg kisebb teljesítményű és nagyobb fogyasztású lesz, de nem kizárt, hogy összetettebb feladatokban esetleg jobban teljesíthet"
Nem lehet, hogy az Intelt egyszerűen a műszaki racionalitás rovására erőlteti a x86-ot? Mert akkor majd úgy kell nekik, ha megint beégnek...
-
Pikari
addikt
azért az már kicsit túlmutat a kényelmi kérdésben, hogy a programozók 99,9%-a (igen, hasraütés!) egyáltalán nem használja (persze a compiler révén igen). ez szinte már-már legitimizációs kérdéseket vet fel szerintem.
A Dunning−Kruger-hatás az a pszichológiai jelenség, amikor korlátozott tudású, kompetenciájú vagy képességű emberek rendkívül hozzáértőnek tartják magukat valamiben, amiben nyilvánvalóan nem azok.


 ). Szerencsére a Haswell IGP-je már valós Gather4 támogatást kap. A kisebb-nagyobb gyenge pontok mellett azért a Gen7 architektúra már elég jó. Gyakorlatilag a Gather4 para az egyetlen, ami komoly gond. Persze az LLC-be mentő stream out sem a legjobb, de az még benne van az elfogadható kategóriában. Ami viszont elég jó az a compute hatékonyság, és ez első nekifutásra dicséretes. Ha igazak a feldolgozók számáról érkező pletykák, akkor ez a Haswellben is javulni fog valamennyit. Persze a GCN ellen kell is.
). Szerencsére a Haswell IGP-je már valós Gather4 támogatást kap. A kisebb-nagyobb gyenge pontok mellett azért a Gen7 architektúra már elég jó. Gyakorlatilag a Gather4 para az egyetlen, ami komoly gond. Persze az LLC-be mentő stream out sem a legjobb, de az még benne van az elfogadható kategóriában. Ami viszont elég jó az a compute hatékonyság, és ez első nekifutásra dicséretes. Ha igazak a feldolgozók számáról érkező pletykák, akkor ez a Haswellben is javulni fog valamennyit. Persze a GCN ellen kell is.





Új hozzászólás Aktív témák

ph Az új generációs architektúra lényegében az IGP szempontjából fejlődött, de az AVX2 utasításkészlet is hasznos.
- Videós, mozgóképes topik
- Megérkezett Magyarországra az LG 480 Hz-es OLED monitora
- Xbox tulajok OFF topicja
- Előzetes élménybeszámolókon az Elden Ring: Shadow of the Erdtree
- Az iPhone 15 frissítésgaranciát, a 16 szép rendereket kapott
- Diablo IV
- Robot fűnyírók
- Ukrajnai háború
- LEGO klub
- Hivatalos képen a Samsung hajlíthatók
- További aktív témák...

Állásajánlatok

Cég: Ozeki Kft.
Város: Debrecen

Cég: Alpha Laptopszerviz Kft.
Város: Pécs