A HSA előnyei és működése
A HSA rengeteg területre jó, hiszen megkönnyíti a heterogén módon programozható termékek kihasználását. Az AMD egyrészt számít rá az Aparapi szempontjából, így konkrét útiterve van a cégnek a HSA felhasználására, sőt, végső állomásként a HSA konkrétan része lenne a Java virtuális gépnek (JVM).
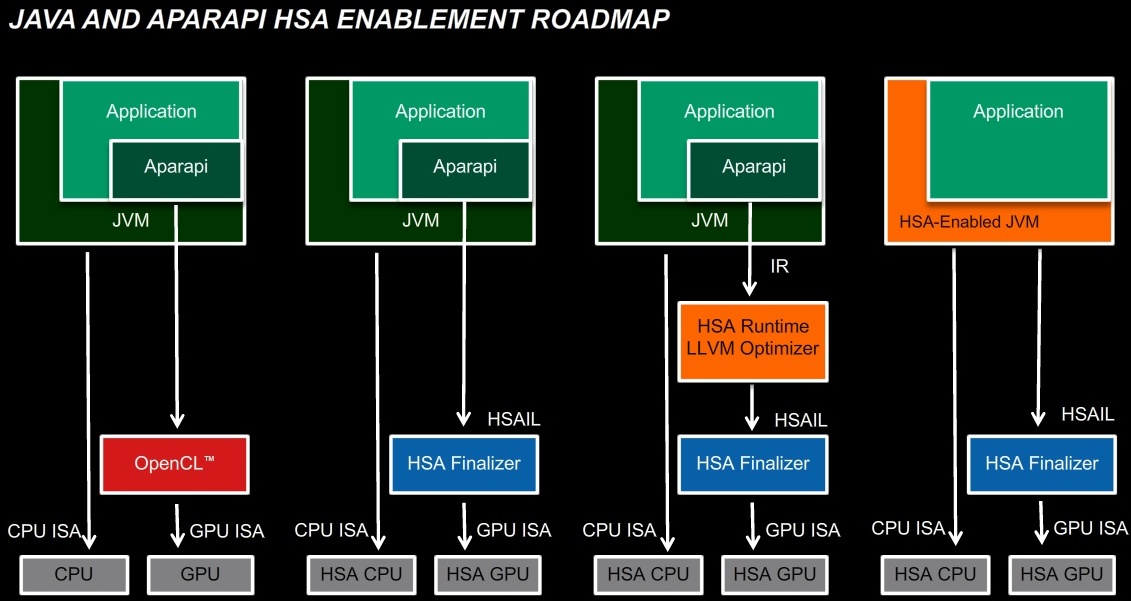
[+]
A logikai modell szempontjából a rendszer az OpenCL, a C++ AMP vagy más egyéb felület és a GPU között helyezkedik el. Áll egyrészt a HSA futtatási környezetből, ami mögött az úgynevezett finalizer és a kernel driver található. Fontos tisztázni, hogy az alapokat egy virtuális ISA (Instruction Set Architecture), avagy magyarul virtuális utasításarchitektúra adja, aminek része egy JIT (Just-In-Time) fordító. A programkódból utóbbi előállítja a HSAIL kódot, mely lényegében a virtuális utasításarchitektúra. Ez kerül a finalizerhez, ami egy másodlagos fordító, mely a kapott programkódot lefordítja a fizikai hardver utasításarchitektúrájára, ezzel pedig a program futtathatóvá válik.
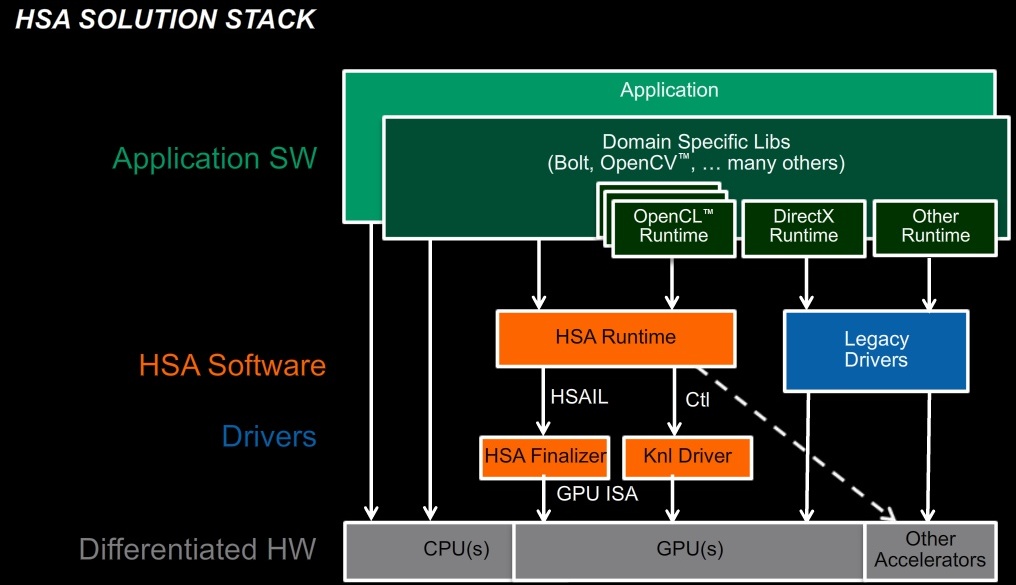
[+]
Az előnyök kézzelfoghatóak, azaz a fejlesztők dolga egyszerűbb lesz. A párhuzamosítást alapvetően a köztes réteg végzi, a memóriamodellt pedig az AMD a C++, a Java és a .NET támogatására tervezte. Mivel virtuális utasításarchitektúráról van szó, így lényegében a fizikai hardver cserélhető alatta. Példával élve, az elméleti működés nagyon hasonló a Java bytecode-hoz, csak az AMD a HSAIL-t kifejezetten teljesítménycentrikusra tervezte.
A támogató cégek számára a rendszer szintén nagyon egyszerű, gyakorlatilag csak a saját hardverekre szabott finalizerről, illetve a kernel driverről kell gondoskodni, a HSA többi eleme univerzálisnak mondható.
A HSA természetesen bővíthető, így az alapítvány tagjai specifikus kiterjesztéseket adhatnak hozzá, mely az adott hardver előnyeit helyezi előtérbe. Az AMD már számos kiterjesztésen dolgozik, és ezek közül a HSA MMU (Memory Management Unit) drivert már véglegesítik, ami része a nemrég bemutatott Trinity APU-nak. Ennek segítségével a teljes rendszermemória elérhetővé válik a CPU és az IGP számára.
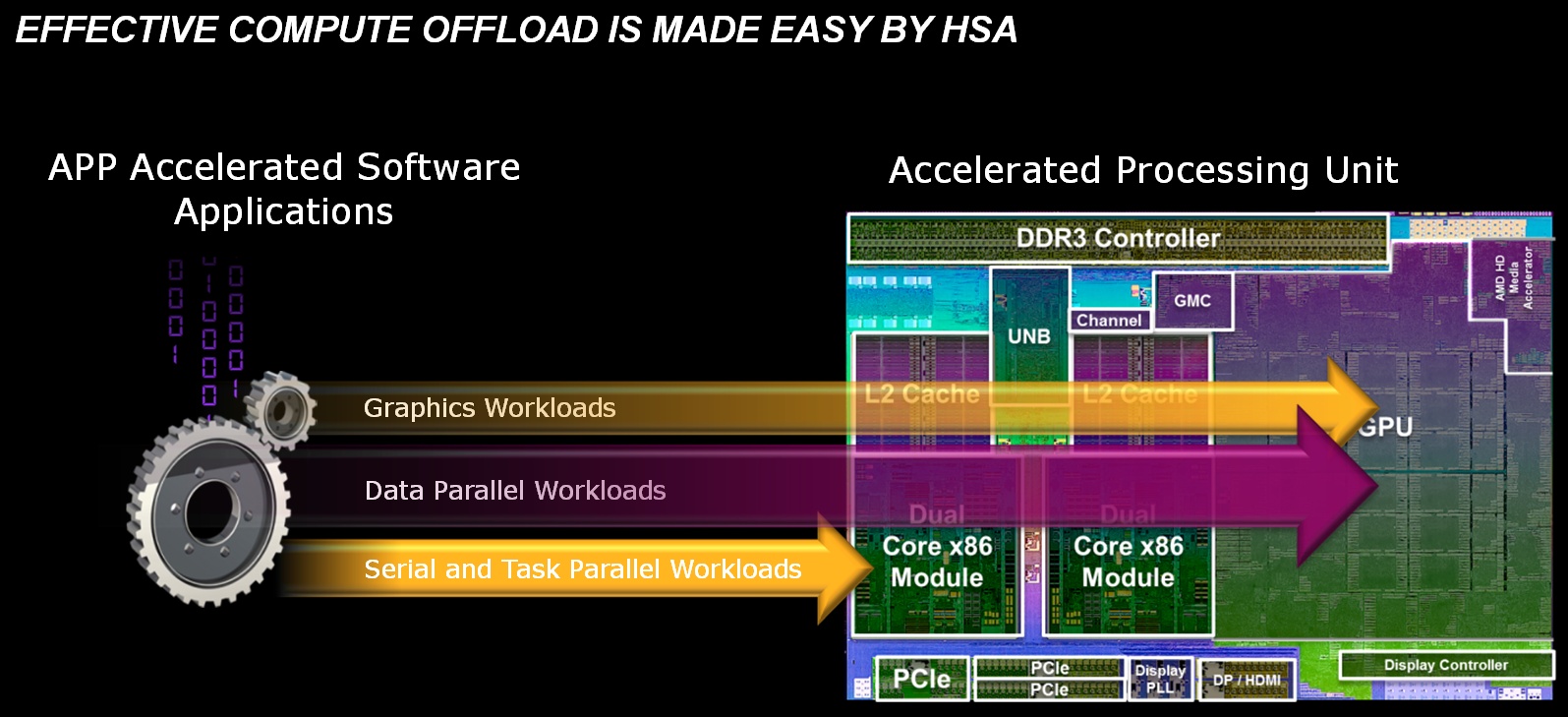
[+]
Phil Rogers kiemelte, hogy az igazán nagy dobás csak jövőre jön, amikor a Kaveri APU-ba beköltözik egy GCN architektúrára épülő IGP. Ezzel megjelenik az egységes címtér, így az IGP ugyanazokat a pointereket kezeli, amiket a CPU, továbbá a grafikus vezérlő képes lesz elérni a processzor virtuális címterét elkerülve az adatok – sok időbe kerülő – másolgatását. Ezenkívül a CPU és az IGP teljesen koherens memóriát oszt meg. Az AMD idővel ennél is tovább megy, és egy későbbi fejlesztésben az IGP preemtív multitaszk képességekhez jut, ami a vállalat szerint rendkívül fontos, mivel a jövőben sokkal több alkalmazás épít majd a grafikus vezérlő erejére, mint a processzormagokra, így elengedhetetlen, hogy ezt a rendszer jól, alacsony késleltetés mellett kezelje. Ennek megfelelően megjelenik a QoS (Quality of Service) is, mely biztosítja a párhuzamosan futó alkalmazások, illetve a párhuzamosan beérkezett felhasználói igények számára a grafikus vezérlő erőforrásaihoz való zavartalan hozzáférést.
A HSA gyakorlati előnyeit le is mérte az AMD különböző feladatokban. Az A10-4600M jelzésű mobil Trinity APU egy OpenCL-ben írt arcfelismerő algoritmust két és félszer gyorsabban futtatott HSA mellett, továbbá képkockánként két és félszer kevesebb energiát is igényelt mindez. Ezzel a cég arra próbálja felhívni a figyelmet, hogy a HSA nemcsak a teljesítményben lehet hasznos, de a fogyasztásra is pozitív hatással van.
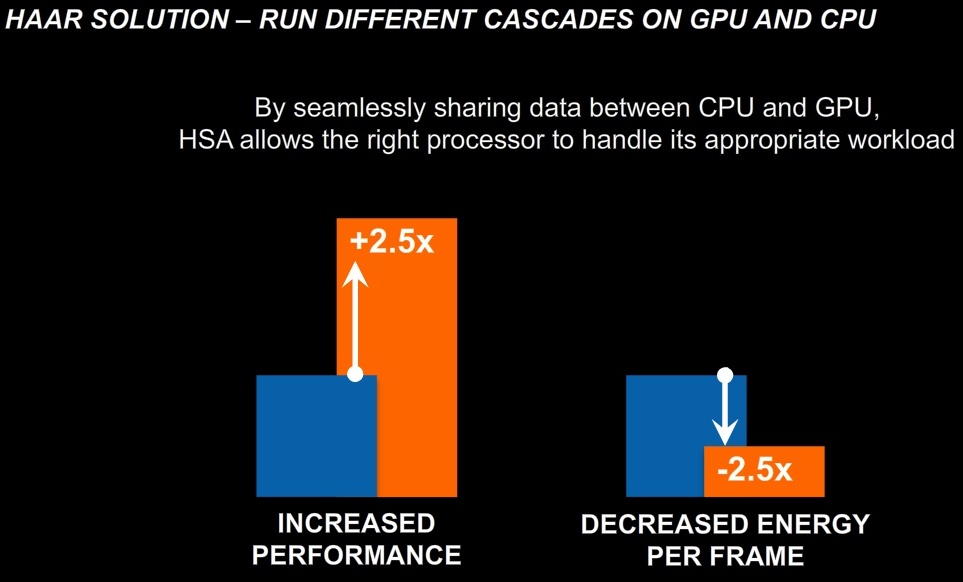
[+]
Programozási szempontból is kielemezték a helyzetet. Az AMD ugyanazt a kódot több felületen is megírta, így össze lehetett hasonlítani, hogy az egyes esetekben hány sort kell beírni. Az első képen látható, hogy egy programszálon könnyű a helyzet, de több szál esetén már több a munka. Az OpenCL ebből a szempontból nem túl jó, noha az OpenCL 1.2 valamelyest javít a helyzeten, de a C++ AMP elfogadhatóbb. A HSA látszik a legkönnyebbnek, de legalábbis nagyon hasonlít az egy programszál esetén befektetett munkához.
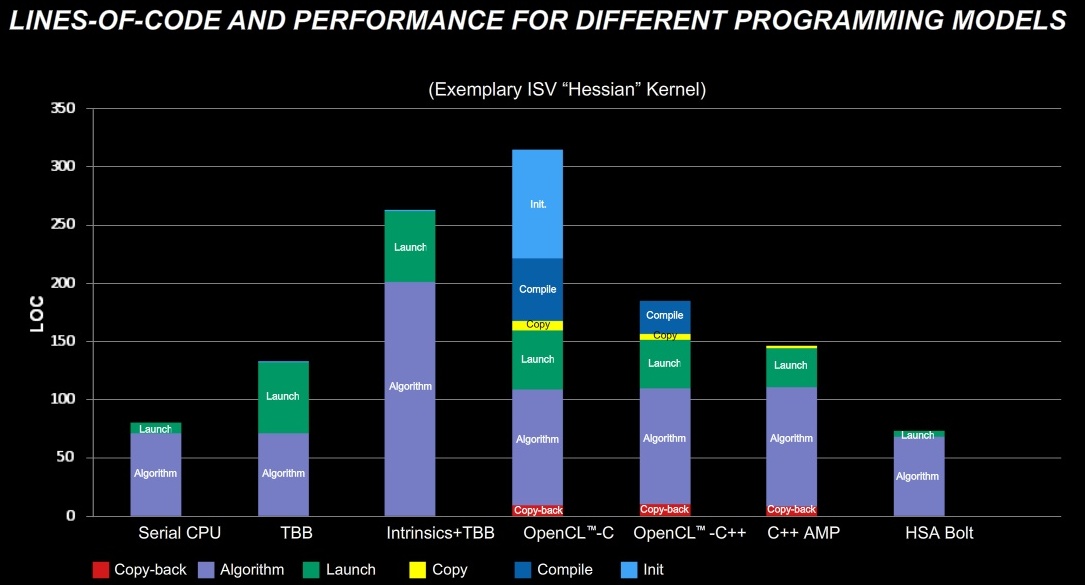
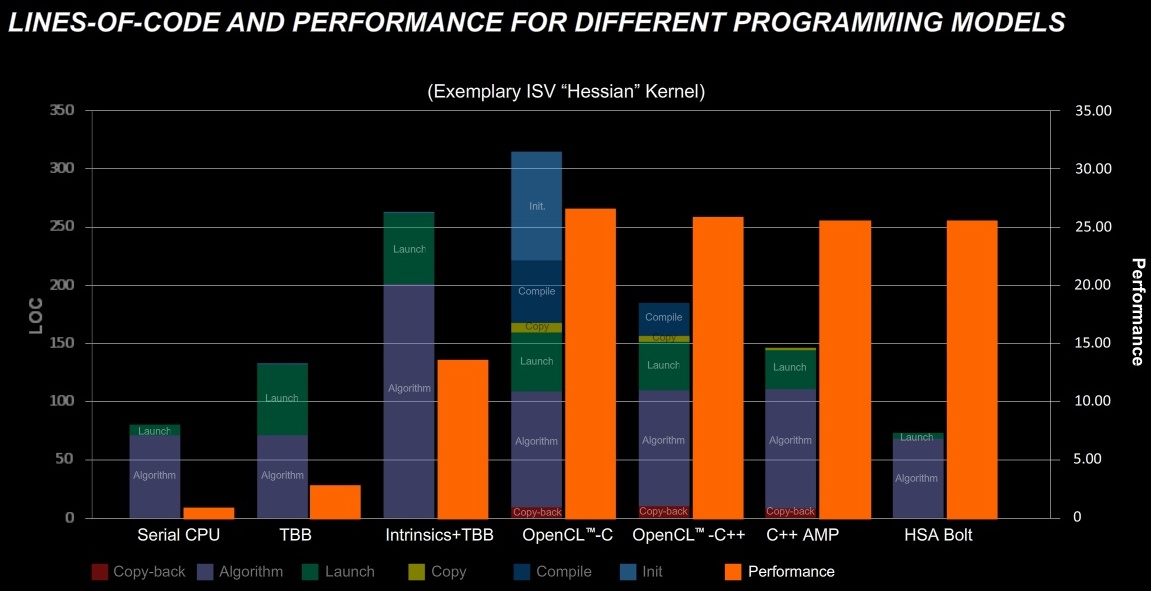
[+]
A teljesítményről a második kép árulkodik, melyről leolvasható, hogy az OpenCL ebből a szempontból a legjobb, de ha a befektetett munka mellett nézzük az eredményt, akkor a HSA toronymagasan nyeri a versenyt.
A HSA-t egyelőre csak az AMD szemszögéből lehet tárgyalni, mert az alapítvány többi résztvevője még nem vázolta fel vízióját. Persze nem nehéz kitalálni, hogy az ARM és az Imagination Technologies miből szeretne hasznot húzni, hiszen az ultramobil termékek piacán a fogyasztás a legfontosabb, és az IGP-k rendkívül energiahatékonyan végzik a jól párhuzamosítható feladatokat. A Texas Instruments szintén érdekelt ezen a piacon, ráadásul az OMAP platformokban saját fejlesztésű hardveres blokkokat is használnak, és valószínűleg itt is előnyt jelent a HSA. A MediaTek a tévépiac második legnagyobb szereplője, és a HSA-val piacvezető szerepre hajthat, továbbá a cég már felvázolta, hogy hamarosan az okostelefonok szegmensét is megcélozzák.
Később valószínűleg tisztább lesz a kép, illetve a rendszer ismeretében több cég belépésére is van esély, mivel a problémák egységesen sújtanak mindenkit. Az NVIDIA a CUDA-t képes megfelelő irányba fejleszteni a Tegrához, de a többi ARM-os szereplőnek szükséges egy saját felület, amelyet ha nem kezdtek el korábban fejleszteni, akkor az egyetlen értékelhető opció a HSA alapítványba való belépés, így szerezve meg a jogot a HSA használatára.
Abu85








