Hirdetés
-


Toyota Corolla Touring Sport 2.0 teszt és az autóipar
lo Némi autóipari kitekintés után egy középkategóriás autót mutatok be, ami az észszerűség műhelyében készül.
-


Három éve fontos döntést hozott az AI-ról az Apple
it A Bloomberg szerint saját chipekkel működtetné az AI-szervereket az Apple.
-


Megérkezett a Corsair új M.2-es SSD-je, és mindennek mondható, csak lassúnak nem
ph Az MP szériás konstrukció egyelőre csak 4 TB-os tárhelymérettel tehető kosárba, és lineáris lemezműveletekben bőven 10 GB/s felett teljesít.






Új hozzászólás Aktív témák
-

Pikari
őstag
,,mikor ennyi?''
ezt is max az intel tudná neked megmondani.,,mennyi a maximum?''
azt én nem tudom neked megmondani, max az intel. én max egy elnagyolt tippet tudok adni: 40 (de fogadni azért nem fogadnék rá),,Kérlek mondj olyan utasítást, amely 128 vagy 256 bites lebegőpontos számokkal dolgozik; vagy innen olyan adattípust!''
nemtom megnyitni a dokumentumot. NEM TUDOM, hogy van -e rá utasítás az általad linkelt dokumentumban, vagy leírás arra, hogy hogyan használhatod fel, vagy hogyan kell konvertálgatni, hogy felhasználhasd, de a long double pl 128 bites (i386 archon 80 bites, compiler függő) az kb 15 éve működő félig meddig processzor szintű, félig meddig szoftveres szintű feature...
,,hanem hogy n elemű tömb(ök)re ugyanannyi műveletből álló for-jellegű ciklus n helyett - adattípustól függően - csak n/2, n/4, ..., n/32 alkalommal fusson le''
megint csak makes no sense.
akkor gondolom nálad az FMA sem SIMD, hanem a gerinchúrosok körébe tartozik
,,AIDA-mérésben''
az aida nem releváns ilyen kérdésekben, soha nem is volt az. fogd meg szépen az intel hivatalos MIPS értékeit, majd hasonlítsd össze a magok számával és az órajellel. meg fogsz lepődni. örömteli, hogy elkezdted legalább a lebegőpontos számok működését tanulmányozni, mielőtt ilyen pointless vitákba vágsz bele, de akár a processzorok felépítésének is utánanézhetnél.,,Mutatsz ebben az AIDA-mérésben''
mi az hogy *ebben*? ki vagy te, hogy meghatározod, hogy én honnét mutathatok mit? egy kissé el vagy tévedve szerintem,,Adhatsz linkeket, hivatkozásokat bőven, gondolom, nem magadtól találod ki ezeket.''

gondolom erről a képről sem látod azonnal, hogy vajon mi lehet annak az oka, hogy miért nem tudod megmondani, hogy egy utasítás hány órajel alatt fut le.
szerintem a beszélgetésünk itt befejeződött, mr mutasdmeginnét level 5[ Szerkesztve ]
A Dunning−Kruger-hatás az a pszichológiai jelenség, amikor korlátozott tudású, kompetenciájú vagy képességű emberek rendkívül hozzáértőnek tartják magukat valamiben, amiben nyilvánvalóan nem azok.
-

P.H.
senior tag
A 40 órajeles tipped mire alapozod?
Azt, hogy a long double 128 bites, mire alapozod?
Az FMA nem SIMD, csak egy művelet, mint az összeadás vagy az osztás: van skalár formája (pl. VFMADDSS), ami csak 1 számpárt szoroz össze és hozzáad egy harmadikat, és van SIMD formája (pl. VFMADDPS), ami több számpárt szoroz össze egyszerre, majd a eredményekhez hozzáad egy-egy harmadik számot, így több eredmény lesz ugyanannyi idő alatt.
Mint írtam a végén, bármit linkelhetsz, nem kell az én linkjeimre hagyatkozni.
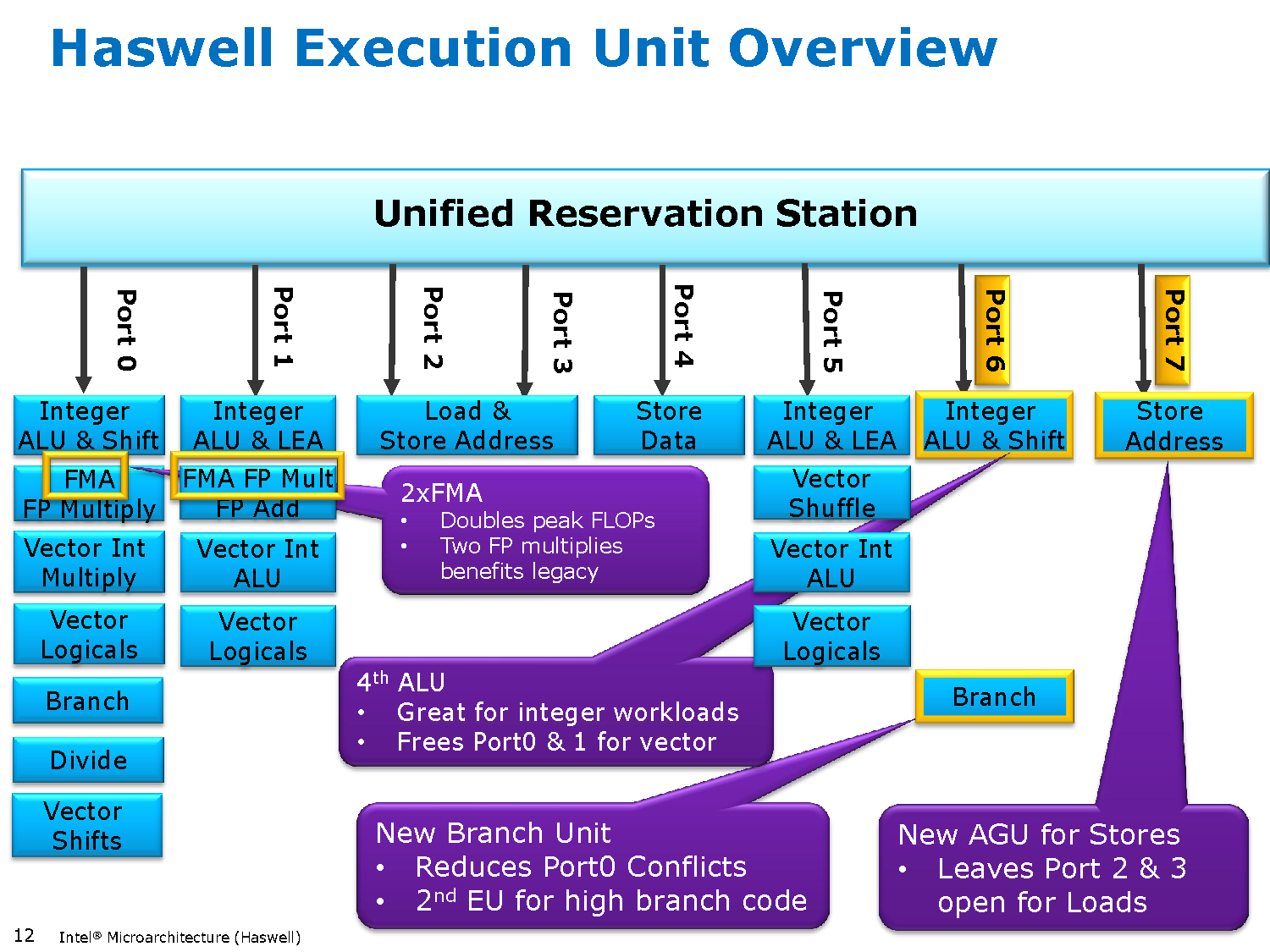
A kép egy pipelined execution unit végrehajtás-idődiagramja, amely fél órajelenként 1 utasítást küld tovább (double-pumped); nincs ebben semmi szokatlan vagy érdekes (csak nem érted, mi van rajta): a gyártók által megadott latency-k az Execute lépcsőre vonatkoznak (az állhat utasítástól függően változó számú lépcsőből*), az meg lemaradt az ábráról; már csak ott kapcsolódunk be, hogy a lefutás után kiírja az eredményt (Data1/Data2/Tag Ch./Write).
*itt a K7 (Athlon XP, Barton pl.) pipeline-ja:
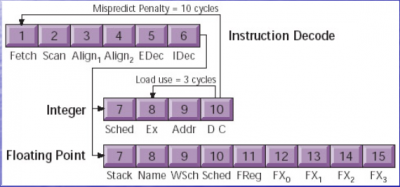
Az integer (egész számos SISD) utasításoknak egyetlen lépcsője van (Ex) a Sched (=ütemezés után; az Addr és DC lépcső a cache-hozzáféréshez kell csak), le is fut mind 1 órajel alatt, a lebegőpontos számoknak 5 (FReg, FX0-FX3); viszont tudjuk a gyártói információkból és a mérésekból, hogy nem mindegyiknek kell végigmennie mind a 5-en, van, amely 2 órajel alatt eredményt ad. A write-back lépcsői ezen nincsenek rajta, mivel nem szükségesek a következő függő utasítás indításához.
Ezen (Atom pipeline) viszont rajta vannak (itt pedig a több EX-lépcső nem szerepel, pedig van):

[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
Pikari
őstag
na látom, normálisabb hangnemre álltál, tehát beszélgethetünk értelmesebb hangnemben is.
,,Azt, hogy a long double 128 bites, mire alapozod?''
a sizeof(long double)-re szokás alapozni,,FMA'',
az most mindegy.
http://en.wikipedia.org/wiki/FMA_instruction_set
van az FMA nevű utasítás, aztán van egy ilyen simd utasításkészlet, a lényege, hogy ezt a KÉT műveletet (szorzás és összeadás) végezd el. a simd lényege nem csak az, hogy tömbökön végezhess el monolitikus feladatokat, ugyanúgy a lényege az is, hogy az utasításokat összevonják olyan módon, hogy például egyszerre ezt a két műveletet meg tudd csinálni több számon. te kategorikusan letagadtad ezt, amikor azt mondtad, hogy a simd nem egymást követő utasítások kötegelésére való. De. erre IS való. a simd lényege az, hogy megspórold az utasítások kiadását. ennek az egyik módja az adattömbök kötelegelése, a másik módja pedig az utasítások kötegelése, mint az FMA instruction set esetében. de ez nem újkeletű dolog, van pl az SSE1-ben RSQRTF, ami a gyökvonást és az osztást kötegeli egybe. hogy ez mostmár inkább kezd közeledni VLIW -hez, vagy inkább még SIMD. az már egy másik ideológiai kérdés, mindenesetre x86on az SSE része lett.a kép, és a többi:
mondhatni igen. a lényege igazából az, hogy ebből nem egy van, mint ahogy ezt talán említetted is, hanem van belőle mindjárt procitól függően magonként 2-3-4-whatever. éppen ezért egy valódi kódban sosem tudhatod, hogy mennyi lesz az utasításod végrehajtásának ideje, még az adott procin sem, hanem függ az előtte és mögötte kiadott utasításoktól, és ezen utasítások számától is. üresjáratban pörgetni nincs értelme. persze van, ha az ember benchmarkolni akar, de valódi felhasználás számára ez inkább csak egyfajta tájékoztató jellegű dolog. a 40-et hasraütésre mondtam, igazából fogalmam sincs, én szélsőséges esetekben ehhez hasonló extrém értékekkel szoktam találkozni - szerencsétlenségemre főleg olyan helyeken, ahol igazán kéne a teljesítmény. nem lehet megjósolni, hogy az adott utasítás hány órajelet fog megzabálni. egy sima integer reg+=reg összeadásra lehet azt mondani, hogy nagyjából kijön 0.5-3 órajelből minden körülmények között, de a komolyabbakra sajnos már nem igazán. a simd utasítások valódi felhasználás során pedig rengeteget kajálnak, nekem ez a tapasztalatom.[ Szerkesztve ]
A Dunning−Kruger-hatás az a pszichológiai jelenség, amikor korlátozott tudású, kompetenciájú vagy képességű emberek rendkívül hozzáértőnek tartják magukat valamiben, amiben nyilvánvalóan nem azok.
-
P.H.
senior tag
Sejtettem: a sizeof(long double) csak játék a fordító részéről (align miatt), 128 bitet foglal le neki, de az adattartalom csupán 80 bit. Ilyesmit már a 90-es évek óta csinálnak a fordítók.
Szerinted mindegy, amúgy nem, nincs helye "is" szónak, a SIMD nem arra való.
RSQRTF nincs az x86-on, az nVidiánál van CUDA-ban.
A VLIW megint teljesen más.Az 2-3-4-whatever ugye vicc?. Ezek gépek, terv szerint működnek, minden előre tudható (már csak azért is, mert le kell teszteni, validálni a CPU-t). Valamint egy processzor két dologra jó: kitenni egy vitrinbe, ha már elég öreg, illetve programokat futtatni rajta; mindkét esetben mi értelme lenne elhallgatnia a gyártónak, hogy mi az adott CPU-n a legjobb programok, az optimalizáció és végső soron a működésének titka? Üzleti érdeke is, hogy az övén fussanak leggyorsabban a programok, amit mások csinálnak.
Ha írnál kézzel assembly kódot, akkor tudnád, hogy a megadott értékek igazak; úgy, hogy közted van egy fordító vagy egy/több köztesréteg, elveszett a talaj, a számokra nem alapozhatsz. De attól még azok a számok igazak maradnak, csak már nem tapasztalhatóak a valóságban, mert nem tudod, mi (és a fordító által mennyivel több minden) is történik valójában, mint amit akartál.
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
Pikari
őstag
Beismerem, tévedtem! valójában nincs is olyan adattípus már vagy 15 éve, hogy long double, csak most találtam ki! a lebegőpontos számokat AMD64 óta valójában nem is SSE2+aboveval számolják, tehát nyilván ezeket sem! a processzormagban nincs több pipeline, se elágazásbecslés! minden dekódolás egyfázisú, tehát a képet, amit belinkeltem, most hamisítottam paintban, és lefizettem az arstechnica rendszergazdáját, hogy töltse fel, csak azért, hogy szivassalak, és összezavarjam a megkérdőjelezhetetlen tudásod. Minden annyi órajel, amennyit az intel ráír, és RSQRTF sincs x86on! Soha életemben nem írtam még assembly kódot, éppen ezért találhattam ki azt, hogy azt hazudom, hogy van RSQRTF, pedig valójában NINCS! De téged nem lehet átverni, hisz te tudod, hogy nincs. http://asm.inightmare.org/opcodelst/index.php?op=RSQRTSS ezt a linket is csak most hamisítottam, aztán meg a microsoftot is lefizettem, hogy kamuzzák be az msdnre http://msdn.microsoft.com/en-us/library/2h228y72%28v=vs.80%29.aspx ! NINCS RSQRTF!
NEKED VAN IGAZAD! Te egy hős vagy, tudásod immár megkérdőjelezhetetlen.
én pedig egy tré tróger ember vagyok, aki hazudtam mindenről...
hazudtam reggel, délben, és este. minden az én hibám! én vagyok a hülye! én vagyok az, aki nem ért hozzá!summa summarum, az én kurva anyámat!
[ Szerkesztve ]
A Dunning−Kruger-hatás az a pszichológiai jelenség, amikor korlátozott tudású, kompetenciájú vagy képességű emberek rendkívül hozzáértőnek tartják magukat valamiben, amiben nyilvánvalóan nem azok.
-
P.H.
senior tag
#109: ?
#108: nem, a SIMD az az RSQRTPS.
Nem találom, hol mondtam ezeket.
Semelyik linkben nem látok RSQRTF-et, csak RSQRTSS-t: közelítő négyzetgyököt számol egyetlen 32 bites lebegőpontos számra (skalár, a SIMD párja az RSQRTPS).
Erre gondoltál: [link]
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
Pikari
őstag
válasz
 #95904256
#106
üzenetére
#95904256
#106
üzenetére
rsqrtf, mint reverse suqare root, floatra. x86on az ezt kivitelező simd utasítás neve RSQRTSS
(RSQRTSS--Scalar Single-Precision Floating-Point Square Root)(de ennél mélyebbre lehetőleg már ne süllyedjetek, a saját érdeketekben)
A Dunning−Kruger-hatás az a pszichológiai jelenség, amikor korlátozott tudású, kompetenciájú vagy képességű emberek rendkívül hozzáértőnek tartják magukat valamiben, amiben nyilvánvalóan nem azok.
-
Pikari
őstag
,,és nem oszt semmit semmivel''
http://4.bp.blogspot.com/-8cGK-05f3oI/T0FOSEvROsI/AAAAAAAABGc/sHYKf5cVLi4/s1600/Jackie-Chan-Meme.jpg
A Dunning−Kruger-hatás az a pszichológiai jelenség, amikor korlátozott tudású, kompetenciájú vagy képességű emberek rendkívül hozzáértőnek tartják magukat valamiben, amiben nyilvánvalóan nem azok.
-

#95904256
törölt tag
Valóban szórakoztató.
Pongyolán foglamaz, rengeteget személyeskedik és egy csomó mindenről halvány lila fogalma sincs, csak dobálózik velük. A "szakmai halandzsa" találó. Pl. "...a gyökvonást és az osztást kötegeli egybe...". A mögötte lévő összefüggések, itt pl. az, hogy a gyökvonás reciprokát kiszámító algoritmus sokkal gyorsabb iterál, teljesen lényegtelen a számára. Szó sincs semmiféle kötegelésről, egyszerűen hamarabb ad eredményt.
-
P.H.
senior tag
#110 és #111: Ez csak szórakozás volt, sikerült kihozni megint az igazi 'Geri'-t.
ON:
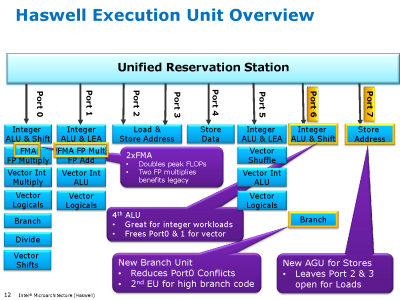
Ez egy igazi tock lesz (kívülről nem nagyon látható, de teljesen átdolgozott belsővel): a Core2 kapott utoljára plusz végrehajtó egységeket és az FMA 5 órajeles késleltetése (ami megegyezik az egyszerű szorzás időigényével) azt sejteti, hogy a belső RISC műveletek mostmár tényleg 2 helyett 3 forrásregiszterrel bírnak (eddig 2 volt, minden jel szerint PPro óta, tehát ez egy elég radikális váltás), mint eddig az AMD-ké.
Ez náluk egy új út kezdete, mint kb. a Bulldozer. Az AVX kimondottan ki lesz bővítve az Intel-nél hamarosan 512 illetve 1024 bitre (nem az IPG veszi át ezt a szerepet), csodálnám, ha az AMD közvetlenül követné 1024 bitre őket; ezzel látható, mivel akar versenyezni az Intel.[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
Pikari
őstag
csak azért vagyok morcos erre a procira (leszámítva azt, hogy amúgy a fenti flameben természetesen igazam van), mert több magot szeretnék.
A Dunning−Kruger-hatás az a pszichológiai jelenség, amikor korlátozott tudású, kompetenciájú vagy képességű emberek rendkívül hozzáértőnek tartják magukat valamiben, amiben nyilvánvalóan nem azok.
-
Pikari
őstag
,,Intel-nél hamarosan 512 illetve 1024''
elképzeltelek, ahogy húzkodod majd magad után az új procit, mint ovodás a bilit, és örömködsz, hogy ,,jaj, mostmár 64 floatot tudok egyszerre összeadni 5 (sic) órajel alatt''. már érzem is az 1% gyorsulást azokon a programokon, ahol az intel kikönyörgi, hogy próbáljanak találni valami helyet, ahol felhasználható lesz majd az az új feature. cpu fiaim, diszappojntálódni vagyok kénytelen bennetek.A Dunning−Kruger-hatás az a pszichológiai jelenség, amikor korlátozott tudású, kompetenciájú vagy képességű emberek rendkívül hozzáértőnek tartják magukat valamiben, amiben nyilvánvalóan nem azok.
-

dezz
nagyúr
Vajon labdába rúghat ez vagy az (512/1024 bit) pl. a CGN-féle CU-k mellett? Főleg, ha abból egy bekerül majd az FPU helyére is? Illetve a HSA-féle "átszervezés" után/közepette?
(#115) Pikari: Igenis, ősapánk...!

Komolyan, te véletlenül nem egy a '90-es években nyugdíjazott számtechtanár vagy? Hogy a mai GPGPU-s metódust kritizálod, az egy dolog, de hogy még a SIMD elvet is...Számos területen meghatározó szerepe van!
Hogy a mai GPGPU-s metódust kritizálod, az egy dolog, de hogy még a SIMD elvet is...Számos területen meghatározó szerepe van! -
-
P.H.
senior tag
Ez több szempontból is nehéz kérdés:
- egyrészt azért, mert nem vagyok jós
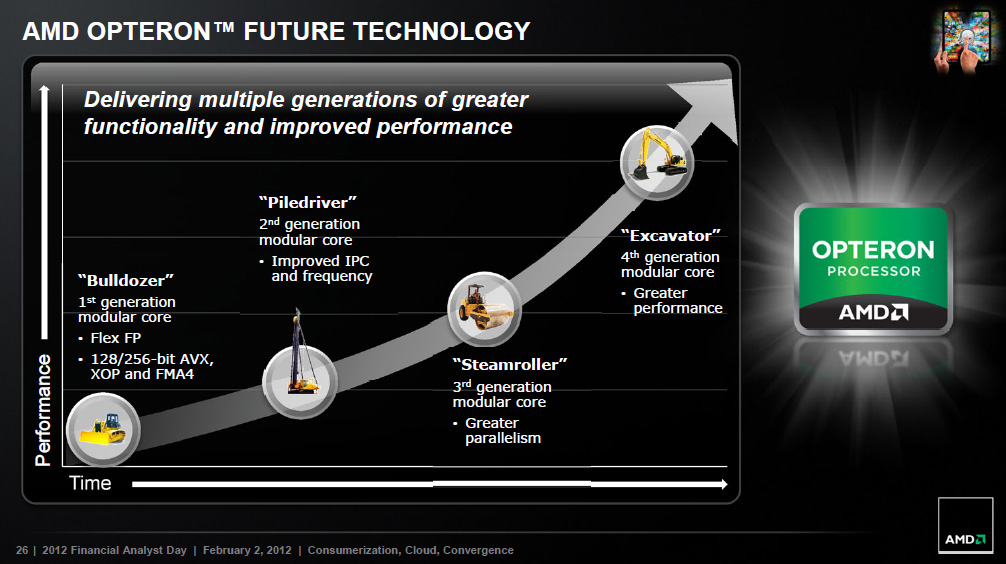
- másrészt azért, mert ez az ábra valószínűleg nem véletlenül zárul az Excavator-ral
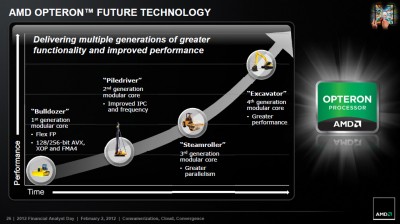
A Bulldozer-vonallal és ezzel a képpel úgy vagyok, mintha az Intel fejlődése lenne felgyorsítva:
+ Bulldozer = Pentium Pro: az alap, elsősorban szerver-orientált; egyik sem váltotta meg a desktop-világot
+ Piledriver = Pentium 2/3: elsősorban órajel-fejlesztések (ha nem is akkora boost, mint a Coppermine volt), mobil területre betörés
+ Steamroller = Pentium M: az egyik legnagyobb kerékkötő, a decode látványos fejlesztése (Intelnél a micro-fusion volt ez), ezzel igen hatékony mobil alternatívává tétele
+ Feltételesen a folytatás: Excavator = Core2? Ha behozzák végre az AGLU-kat, akkor nagyot erősödik az utasításvégrehajtás (~ a szélesség), beérne végre a teljes vonal.- harmadrészt ezt az ábrát nézve

nem biztos, hogy az FPU lesz lecserélve GCN-re; inkább egy-egy teljes modult válhat ki egy-egy CU. Egy 16 Kb 4-utas write-through L1D-vel és 16 utas L2-vel felszerelt CU-t GLC=1 állásban nem tud semmilyen más egység kívülről megkülönböztetni egy CPU-modultól és a CU-k a jelenlegi 512 bites vektor-egység mellett (a GPU-khoz képest) jól fejlett - és eléggé x86-közeli - skalár/fixpontos/integer egységgel is fel vannak szerelve.
Ha az Intel majdan egy gyűrűre felfűz néhány CPU-mag mellé pár Larrabee-magot (amik mindegyike x86-alapú), akkor az AMD miért ne tenné meg ugyanezt a felfűzést (a HSA-ra mint vISA-ra alapozva) néhány CPU-modul + tetszőleges számú CU felállásban?[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-

Abu85
HÁZIGAZDA
Két részre kell bontani a kérdést. El lehet érni így is a megfelelő throughput teljesítményt ilyen homogén iránnyal, de csak akkor, ha a fogyasztást másodlagos tényezőként kezelik (szerverekben tolják is ki a TDP limiteket már a következő generációnál). Ha a mobil irányt ide vesszük, akkor egységnyi fogyasztás mellett semmi esélye olyan throughputot elérnie egy ilyen rendszernek, amilyenekkel az IGP-k dolgoznak. A felét talán lehet hozni, de akkor is az Intel homogén megvalósításának lesz a legnagyobb fogyasztása, beleszámolva két node előnyt (persze a Dennard Scaling hanyatlásával ez egyre kevesebbet ér). Ez a koncepció akkor érne valamit, ha az NTV technológiák már most bevethetők lennének, de egyelőre még kísérleti fázisban van.
Az AVX-1024-re inkább logikai szempontok szerint lenne érdemes gondolni. Már 512 bitre ki van terjesztve a Larrabee-ben. A következő lépcső az 1024 bit. Na most nem kötelező ám 1024 bites AVX utasításokat ilyen széles feldolgozókon végrehajtani. Lehet akár 256 biteseken is. Az látszik a Larrabee-n, hogy az Intel Pollack szabályát veszi figyelembe, ami ugyanolyan gyógyír a Dennard Scaling hanyatlására, mint a GPGPU.
Az Intelnek a rendszerszintű integrációja az olyasmi lehet, hogy megvan a gyűrűs busz alapnak, amire ott az LLC. A tárat le kell cserélni egy SRAM-nál jobb sűrűséget adó megoldásra. eDRAM is jó, ha az FBC nem jön be. A lapkában meg lesznek a magokhoz való szeletek, a gyűrűs busz, és azokra fel lesz fűzve x CPU-mag és "jóval több mint x" Larrabee mag. A Larrabee Pollack szabályára építkezik, míg a CPU-magokat meg kell tartani az értékelhető egyszálú teljesítményért. Az AVX támogatást egységesíteni lehet a két mag között, vagyis a Larrabee kaphat 1024 bites feldolgozókat, míg a CPU-magok képesek lehetnek 256 bites feldolgozókkal dolgozni, de ugyanúgy támogathatók az 1024 bites utasítások. És persze a CPU-magok más órajelen kell, hogy fussanak, mint a Larrabee magok, de ez a legegyszerűbb gond amit meg kell oldani a koncepcióban. Én ezt raknám össze, hogy versenyképes maradjak. Nyilván sok a buktatója, és sok a kockázat is, de most ezt fel kell vállalni.A HSA-t szerintem mindenképpen támogatni kell. Vagy, ha azt nem, akkor egy másik hasonló koncepciót. A fejlesztői nyomás itt most óriási lett, ahogy az AMD megmutatta mit tud egy ilyen rendszer. Johan Andersson már kiállt, hogy nem pont a HSA érdekli, hanem az a koncepció, amit az infrastruktúra felkínál a fejlesztőknek. Szerinte ez a jövő, és felszólította az összes gyártót, hogy álljon be mögé, vagy ha nem, akkor egyezzenek meg egy másik hasonló megoldásról, amit tényleg mindenki támogat. Erre egyébként az Intel kivételével szerintem mindenki hajlandó lenne, hiszen ellenérvet nehéz felhozni ellene. Az Intelnek az a baja, hogy a HSA, vagy a HSA-hoz hasonló koncepcióval teljesen bukó a felépített monopóliumuk. Gyakorlatilag az x86 mint jelenlegi erős érték szart sem fog érni.
A HSA azért opció, mert annak már kész van az 1.0-s draft specifikációja, és az úgy van kialakítva, hogy könnyű legyen támogatni a hardver oldaláról. Emellett a HSA-nál nyíltabb alternatíva aligha lesz. Minden alapító besorolású tag egységes anyagi támogatást ad, egységes a szavazati jog, egységes a beleszólás, egységes a marketing, szóval akár csinálnak mellé még egy másik alternatívát ennél egységesebb formai működést az sem tud majd felmutatni.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#95904256
törölt tag
Abu! Mi a véleményed arról amit dezz említett a #118-asban?
"Ami párhuzamosítható, az legtöbbször SIMD-esíthető is... Ezek után hol ésszerűbb a sok-sok CPU mag?"A GPU-k is rengeteg magot használnak jól párhuzamosítható műveletekre, de miért? Miért nem a sok ezer bit széles feldolgozók alakultak ki?
Energiafelhasználás szempontjából előnyösebbnek tűnik a sok-sok műveletvégzőt kevesebb CPU maggal etetni. Ráadásul a kevesebb magot jobban "ki lehet gyúrni" ( nagyobb órajel, nagyobb cache, stb. ) az egyéb számításokra.
-
dezz
nagyúr
Találó párhuzam.
"inkább egy-egy teljes modult válhat ki egy-egy CU."
Minden bizonnyal. (Egyébként egyes dokumentumokban az AMD a Bulldozer modulokat is CU-nak nevezi.) Bár ez nem zárja ki, hogy az sima modulon belüli FPU is combosabbá váljon előbb-utóbb, ha már úgyis moduláris felépítésűek maguk a modulok is.
(#121) Abu85: Igen, magam is írtam az energiahatékonyságot korábban.
Az Intel persze azzal versenyez, amije van. A Larrabee alapú megoldás valószínűleg kisebb teljesítményű és nagyobb fogyasztású lesz, de nem kizárt, hogy összetettebb feladatokban esetleg jobban teljesíthet (legalábbis a saját peakjéhez képest), mint az AMD-féle, ami nagyobb teljesítményű (peak) és energiahatékonyabb lehet, de ezt talán a nem túl komplex számításoknál tudhatja igazán kamatoztatni. Persze az is lehet, hogy az utóbbi mindkettőben jó lesz, ha a CPU és GPU jellegű CU-k hatékonyan össze tudnak dolgozni.
Nos, ezt Johan Andersson nélkül is tudjuk...
(#122) akosf: CU-nként egy branch unit van... Márpedig feltételes ugrásoknál adott esetben érvénytelenné válhat a teljes aktuális SIMD-es eredmény, az adott CU-ban. Egy bizonyos szinten túl egyre többször nem növeli, hanem csökkenti a teljesítményt a szélesítés.
[ Szerkesztve ]
-
Pikari
őstag
válasz
#95904256
#122
üzenetére
,,A GPU-k is rengeteg magot használnak jól párhuzamosítható műveletekre, de miért? Miért nem a sok ezer bit széles feldolgozók alakultak ki?''
mert nekik volt eszük. SIMD-el csak bizonyos típusú műveletek gyorsíthatók, amik jó, ha 5%-át kiteszik a teljes kódnak (persze ez feladattól is függ, van, ahol 0). több mag esetén pedig azt dobsz szét, amit csak akarsz.
A Dunning−Kruger-hatás az a pszichológiai jelenség, amikor korlátozott tudású, kompetenciájú vagy képességű emberek rendkívül hozzáértőnek tartják magukat valamiben, amiben nyilvánvalóan nem azok.
-
dezz
nagyúr
Vagy 20 vagy akármennyi. Megint a hasadra ütöttél... Különben sem az számít, hogy a teljes kód mekkora része SIMD, hanem hogy a futásidő mekkora részét teszi ki, illetve mennyivel gyorsítja a műveletet. Egyébként pedig a kérdésben benne volt, hogy jól párhuzamosítható. (Más kérdés, hogy van egy ésszerű határa a SIMD szélesítésének, lévén egy valós kód nem csak alap- és egyéb számítási műveletekből áll.)
[ Szerkesztve ]
-
Pikari
őstag
mert a hasamra ütöttem. és gyaníthatólag még mindig közelebb van a valósághoz, mint neked akármilyen más hosszas számításod lenne
azt még azért tegyük hozzá annak, aki még nem látott ilyet, hogy az adott művelet elvégzéséhez szűkséges adatok memóriában és kódban lévő reprezentációja általában nem is teszi lehetővé azt, hogy közvetlenül SIMD utasításokkal lehessen őket bojgatni, hanem át kell másolgatni őket. így sokszor az is előfordul, hogy amit az ember nyer a vámon, azt elbukja a postán.
[ Szerkesztve ]
A Dunning−Kruger-hatás az a pszichológiai jelenség, amikor korlátozott tudású, kompetenciájú vagy képességű emberek rendkívül hozzáértőnek tartják magukat valamiben, amiben nyilvánvalóan nem azok.
-
Pikari
őstag
ez egy kicsit erős kifejezés, hogy hülye lenne. a coder általában igyekszik olyan jellegű kódstruktúrát kialakítani, ami kényelmesen kezelhető, algoritmikailag könnyen átlátható, ebbe csak úgy simán nem vághatsz bele egy SIMD utasítást kézzel, ennek számos oka lehet, például hogy nem is úgy következnek a feladatok az algoritmusban egymás után, hogy triviálisan, ránézésre lehessen SIMD-et használni, a másik pedig, hogy az adatok nem megfelelően alignáltak (mert miért lennének azok).ha az ember SIMD-et akar a szoftverben, akkor azt bizony úgy kell szó szerint belefosni, (persze tekintsünk el ezesetben a fordítóprogram autómatikus SIMDesítésétől, ami általában - pont ugyanezen okok miatt - szintén nem is túl hatékony)
A Dunning−Kruger-hatás az a pszichológiai jelenség, amikor korlátozott tudású, kompetenciájú vagy képességű emberek rendkívül hozzáértőnek tartják magukat valamiben, amiben nyilvánvalóan nem azok.
-

ddekany
veterán
"A Larrabee alapú megoldás valószínűleg kisebb teljesítményű és nagyobb fogyasztású lesz, de nem kizárt, hogy összetettebb feladatokban esetleg jobban teljesíthet"
Nem lehet, hogy az Intelt egyszerűen a műszaki racionalitás rovására erőlteti a x86-ot? Mert akkor majd úgy kell nekik, ha megint beégnek...
-
-
#131
 Ł-IceRocK-Ł
addikt
Ł-IceRocK-Ł
addikt
Ł-IceRocK-Ł
addikt
Kiváncsi leszek a tesztekre.
"lol, rock, te egy kib*szott médium vagy. mit médium, HARD " by FireKeeper
-
dezz
nagyúr
Senki sem mondta, hogy a SIMD-esítés (és párhuzamosítás) a legkényelmesebb programozási forma... Az adatstruktúrát célszerű előre eltervezni. Ennek jelentősége nyilván attól is függ, hogy mennyit is kell "tökölni" a procin belül az adatokkal. Ha jó sokat nem túl sok adattal, akkor a műveletek előtti átrendezés is bőven beleférhet.
(#129) ddekany: Valószínűsíthető. Plusz a meglévő kódbázis viszonylag egyszerű alkalmazhatóságát is próbálják komoly versenyelőnnyé alakítani. Ez nyilván kevésbé hatékony, mint mondjuk egy jól megírt HSA kód, de ezt a gyártástechnológiai előnyükkel és erre építve az egyre több maggal próbálják majd ellensúlyozni (bár ez egyre kevésbé működik, ahogy lassan fő tényezővé válik az energiahatékonyság), emellett az üzleti befolyásukat is latba vetik.
-
Pikari
őstag
azért az már kicsit túlmutat a kényelmi kérdésben, hogy a programozók 99,9%-a (igen, hasraütés!) egyáltalán nem használja (persze a compiler révén igen). ez szinte már-már legitimizációs kérdéseket vet fel szerintem.
A Dunning−Kruger-hatás az a pszichológiai jelenség, amikor korlátozott tudású, kompetenciájú vagy képességű emberek rendkívül hozzáértőnek tartják magukat valamiben, amiben nyilvánvalóan nem azok.
-
dezz
nagyúr
Lehet, de ennél fontosabb, hogy azok azért használgatják, akik olyan programokat írnak, ahol ennek különösebb jelentősége van. Ezeket a teljesítményigényesebb, spécibb programokat nem kezdő/harmadrangú programozók írták általában.
Visszatérve a GPGPU-ra, ami ellen először megszólaltál, nos ott pl. az OpenCL elég jó kompromisszum a hw-közeli programozástól való mentesség és a jó teljesítmény között. A HSA pedig a hatékonyságnövelés és a lehetőségek kiterjesztése mellett nem kicsit egyszerűsíti tovább az egészet.
Az Intel - mivel nagyteljesítményű GPU fejlesztésben nincs túl sok tapasztalatuk - is azzal próbálkozik már évek óta (eleddig nem sok sikerrel), hogy alaposan leegyszerűsített, ugyanakkor széles SIMD feldolgozással bíró magokból pakol többtízet egymás mellé. (Később állítólag az mai IGP-jük helyét is ilyen komplexum fogja átvenni a hibrid chipekben, a néhány hagyományos CPU mag mellett.)
Már elhangzott, miért elkerülhetetlen mindez: a sima CPU magoknak sokkal rosszabb az energiahatékonysága (telj./watt). Ez ott válik kritikussá, hogy hiába csökkentik a csíkszélességet, a fogyasztás nem csökken a kellő arányban ahhoz, hogy a teljes chipterületet ilyen magokkal szórhassák be.
-

siwok1
tag
És lőn világosság!
Komolyan nézne ki egy olyan gép ahol egy CPU van ás többi express foglalatba belel lehetne helyezni Kártyás procikat jelenleg max 7-8 foglalat áll rendelkezésre. Oda bezsufolni ilyen egységeket. összehangolni és CF/SLI nél magasabb teljesítmény növekedés érhető el mert minden egységben van cpu is, és aNV meg ashatja a physXt. : LOL











 Hogy a mai GPGPU-s metódust kritizálod, az egy dolog, de hogy még a SIMD elvet is...Számos területen meghatározó szerepe van!
Hogy a mai GPGPU-s metódust kritizálod, az egy dolog, de hogy még a SIMD elvet is...Számos területen meghatározó szerepe van!






Új hozzászólás Aktív témák

ph Az új generációs architektúra lényegében az IGP szempontjából fejlődött, de az AVX2 utasításkészlet is hasznos.
- Brogyi: CTEK akkumulátor töltő és másolatai
- Samsung Galaxy S23 Ultra - non plus ultra
- Eleglide C1 - a középérték
- The Division 2 (PC, XO, PS4)
- Reklámblokkolók topikja
- Apple notebookok
- Acer Nitro V 15 notebook: amikor a jó ár-érték arány a cél
- Mobil flották
- Iqos cigaretta
- Ukrajnai háború
- További aktív témák...

- Intel Core i7-7700 processzor (használt)
- Beszámítás! Intel Core i3 8100 4mag 4szál processzor garanciával hibátlan működéssel
- Beszámítás! Intel Core i7 2600K 4mag 8szál processzor garanciával hibátlan működéssel
- Beszámítás! Intel Core i9 9900K 8mag 16szál processzor garanciával hibátlan működéssel
- Ryzen 9 5950X
Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: Ozeki Kft.
Város: Debrecen