
Pentium M, Conroe, Penryn
Pentium M
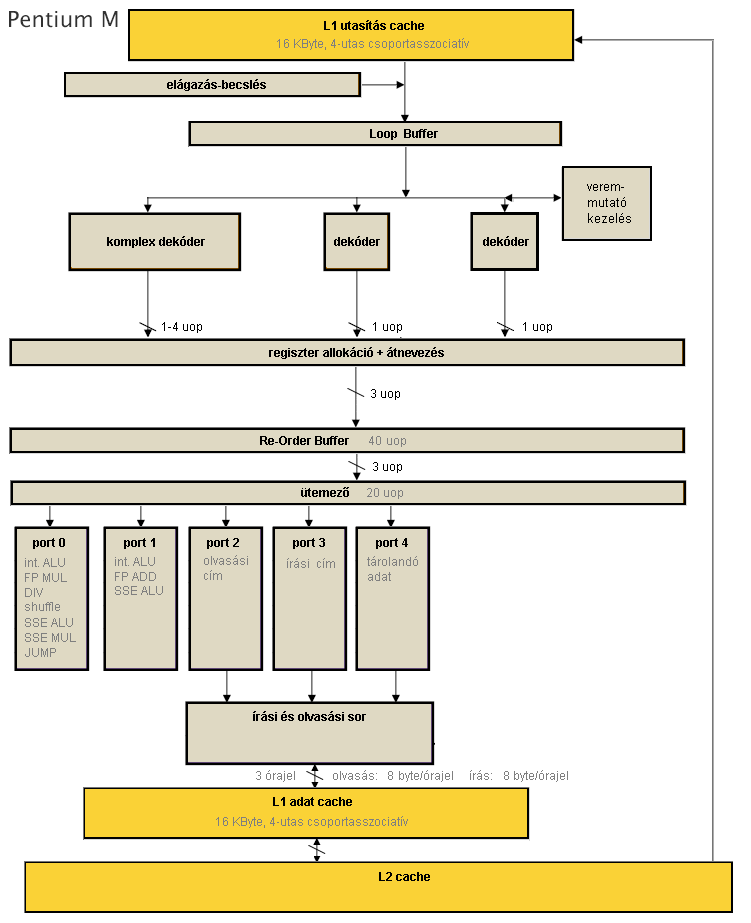
A Core processzorok közvetlen elődjének a Netburst termékvonallal párhuzamosan fejlesztett Pentium M processzorok tekinthetők. Ezek szerkezeti ábrájukban nagyrészt megegyeznek a P6 processzorokkal, viszont több ponton is jelentősen fejlődtek.
[+]
- Bevezetésre kerül az µop-fúzió (micro fusion): a load-op, illetve a store jellegű utasítások 2-2 µop-ját egyetlen egységben dekódolja és tárolja a ROB-ban, majd azok csak az ütemezőben válnak szét és kerülnek külön végrehajtóba. Ennek jelentősége egyrészt, hogy így a két egyszerű dekóder is tudja ezeket az utasításokat kezelni, így sokkal több utasítás kerülhet dekódolásra órajelenként, sokkal kötetlenebb a korábbi szigorú 4-1-1 µop mintájú optimális utasítássorrend; másrészt a változatlan elemszámú belső pufferek effektíve akár kétszer annyi tennivalót is tárolhatnak. Ez a fúzió itt még csak az integer és MMX utasításokra érvényes, az SSE utasításokra nem működik.
- Ugyancsak a dekódolás gyorsítása miatt egy 64 bájtos loop buffert alkalmaznak, miáltal a kisméretű ciklusok utasításcache-olvasás nélkül futtathatók.
- A harmadik jelentős módosítás a veremmutató-kezelő megjelenése a dekódolás során: a függvények paraméterátadására és hívására alkalmas PUSH, POP, CALL és RET utasítások mindegyike hatással van a veremmutató értékére, csökkentik vagy növelik azt. A veremmutató-kezelő egy olyan számláló, amely tárolja a csökkentés/növekedés mértékét, így a veremmutató változatlan maradhat, a tényleges módosítását nem kell végrehajtani, csak a dekóderek belefordítják a veremíró, illetve veremolvasó µop-ba a számláló értékét is.
- Ugyancsak jelentős, a magoknál nagyobb léptékű változás, hogy a Pentium M család kései termékeiben megjelennek a natív többmagos megoldások, amelyek között a nagyméretű megosztott, azaz mindkét mag által közösen használt L2 cache teremt kapcsolatot.
Conroe és Penryn, azaz az 1. generációs Core processzorok
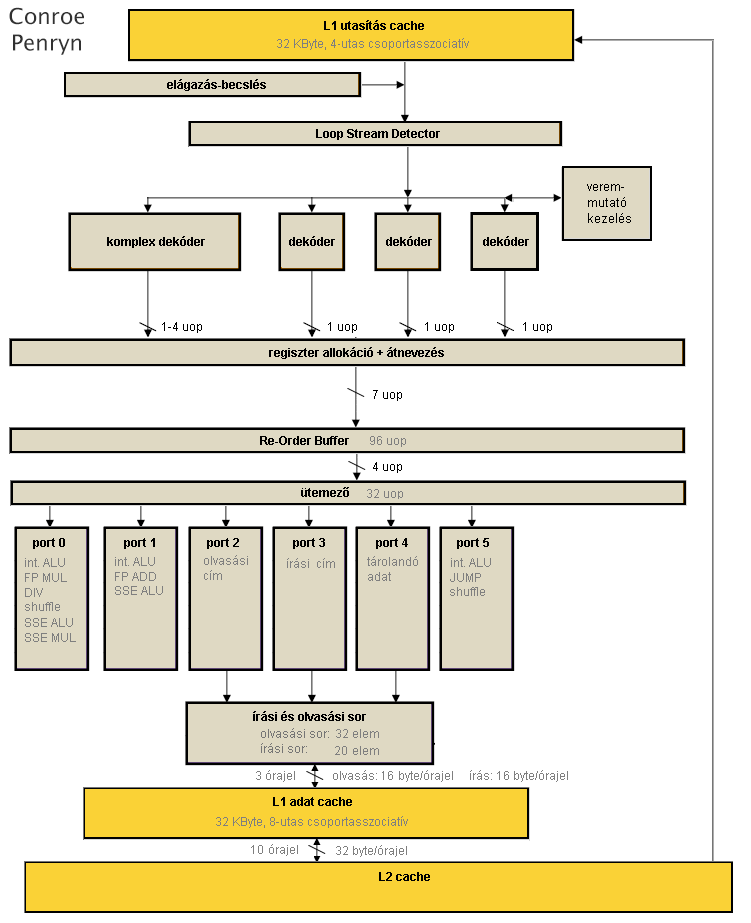
A Pentium 4 processzorok fejlesztésének megszakítása után az Intel asztali felhozatalát az előbb ismertetett Pentium M felépítésre alapozta, ugyanakkor számos ponton "kiszélesítette" azt.
[+]
- A teljes processzor 4 utasítás széles, ennek érdekében 4 dekódert találunk a front-endben, az újonnan beépített fordító is egyszerű, mivel ezzel órajelenként 4 utasítás feldolgozása lehetséges: 1 komplexebb, legfeljebb 4 µop-ot generálóé, és utána közvetlenül sorakozó 3 egyszerű, 1 µop-ra leképezett utasításé.
- Megjelenik az utasítás-fúzió (macro fusion), így két speciális esetben lehetséges 2 db egymást követő x86 utasítás egyetlen µop-ra fordítása: az első instrukció vagy két integer érték összehasonlítása (CMP), vagy két integer érték AND művelettel való tesztelése (TEST); a második pedig az azt közvetlenül követő ugró utasítás. Ezen párok egyetlen CMPJMP vagy TESTJMP belső műveletté fordíthatók le; ez a későbbiekben is elemi belső művelet, nem válik ketté a végrehajtás során sem. Ezt a fúziót a 4 dekóder bármelyike képes megcsinálni, de órajelenként csak 1 ilyen esemény történhet; továbbá ebben a processzorgenerációban csak 32 bites programkódon működik és csak előjeltelen szemantikájú ugrásokra, 64 bites utasításokra még nem, illetve előjeles feltételkódokra sem.
- Teljessé válik a µop-fúzió: immár az összes load-op és store utasítás 2-2 µop-ja egyesítődik, beleértve az SSE utasításokat is.
- A korábbi processzorcsaládok 64 biteseivel szemben az összes SSE utasítás 128 bites végrehajtókat kap, beleértve a memóriahozzáféréseket is.
- Lehetővé válik a memóriaírási műveletek out-of-order módon történő végrehajtása: természetesen a korábbi konvencióknak meg kell felelni, de immár a processzor képes belül teljesen spekulatívan átrendezni egymás között a memóriaolvasási és -írási µop-ok feldolgozását, és ha a véglegesítés közben kiderül, hogy sorrendsértés történt, akkor – egy téves elágazásbecsléshez hasonlóan – újraindítja az utasításvégrehajtást a legutolsó helyes utasítástól.
- A korábbi két, számítási µop-okat végrehajtó egység mellé felsorakozik egy újabb, ezáltal három port között lehet elosztani a kalkulációkat. Számos egyszerű integer µop-ból immár órajelenként 3 futtatható, valamint ezen egység futtatja az összes ugró és fuzionált ugró utasítást.
A cikk még nem ért véget, kérlek, lapozz!





